线性模型
线性模型
1、线性回归
假如咱们有一个数据集,里面的数据是俄勒冈州波特兰市的 \(47\) 套房屋的面积和价格:
| 居住面积(平方英尺) | 价格(千美元) |
|---|---|
| \(2104\) | \(400\) |
| \(1600\) | \(330\) |
| \(2400\) | \(369\) |
| \(1416\) | \(232\) |
| \(3000\) | \(540\) |
| …… | …… |
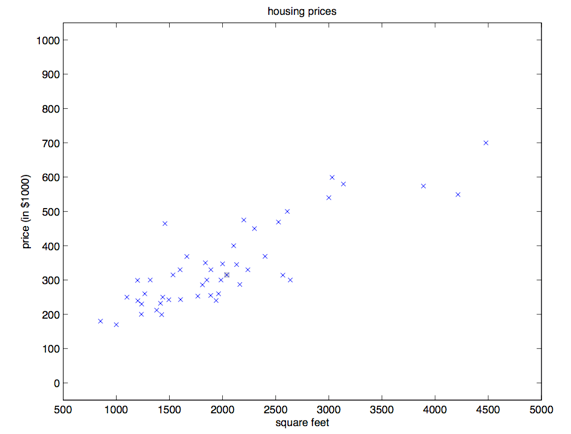
如果来了一个新的面积,假设在销售价钱的记录中没有的,我们怎么办呢?
我们可以用一条曲线去尽量准的拟合这些数据,然后如果有新的输入过来,我们可以将曲线上这个点对应的值返回。这就是线性回归的思想。
为了让我们的房屋案例更有意思,咱们稍微对数据集进行一下补充,增加上每一个房屋的卧室数目:
| 居住面积(平方英尺) | 卧室数目 | 价格(千美元) |
|---|---|---|
| \(2104\) | \(3\) | \(400\) |
| \(1600\) | \(3\) | \(330\) |
| \(2400\) | \(3\) | \(369\) |
| \(1416\) | \(2\) | \(232\) |
| \(3000\) | \(4\) | \(540\) |
| …… | …… | …… |
也是同样的方法,此时的自变量就变成了二维向量。
下面是一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过 程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型。就如同上面的线性回归函数。
线性回归假设特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征 对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
我们用\(x_1\),\(x_2\)去描述feature里面的分量,比如 \(x_1\)=居住面积,\(x_2\)=卧室数目,我们可以做出一个估计函数: \[ h_\theta (x) = \theta_0 + \theta_1 \times x_1 + \theta_2 \times x_2 \] 简化一下就为: \[ h(x) = \sum^n_{i=0} \theta_i x_i = \theta^T x \] 我们程序也需要一个机制去评估我们\(\theta\)是否比较好,所以说需要对我们做出的\(h\)函数进行 评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述\(h\)函 数不好的程度,在下面,我们称这个函数为\(J\)函数: \[ J(\theta) = \frac 12 \sum^m_{i=1}(h_\theta(x^{(i)})-y^{(i)})^2 \] 如何调整\(\theta\)以使得\(J(\theta)\)取得最小值有很多方法,其中有最小二乘法(least squares method)和梯度下降法等。
1.1 最小二乘法
给定一个训练集,把设计矩阵(design matrix) \(x\) 设置为一个 \(m\times n\) 矩阵(实际上,如果考虑到截距项,也就是 \(\theta_0\) 那一项,就应该是 \(m\times (n+1)\) 矩阵),这个矩阵里面包含了训练样本的输入值作为每一行:
\[ X =\begin{bmatrix} (x^{(1)}) ^T\\ (x^{(2)}) ^T\\ \vdots \\ (x^{(m)}) ^T\\ \end{bmatrix} \]
然后,咱们设 \(\vec{y}\) 是一个 \(m\) 维向量(m-dimensional vector),其中包含了训练集中的所有目标值:
\[ Y =\begin{bmatrix} y^{(1)}\\ y^{(2)}\\ \vdots \\ y^{(m)}\\ \end{bmatrix} \]
假设\(h_\theta(x_1,x_2,...,x_m)=\theta_0+ \theta_1 \times x_1 + \theta_2 \times x_2 + ... +\theta \times x_m\) 的矩阵表达式为 \[ h_\theta(x)=X_\theta \] 损失函数定义为: \[ \frac \partial {\partial\theta_j}J(\theta) = \frac12 (X_\theta - Y) ^ T (X_\theta - T) \] 这时候我们要对这个损失函数的 \(\theta\) 向量进行求导取0,结果如下式: \[ \theta = (X^T X)^{-1} X^T Y \]
1.2 梯度下降算法
我们希望选择一个能让 \(J(\theta)\) 最小的 \(\theta\) 值。怎么做呢,咱们先用一个搜索的算法,从某一个对 \(\theta\) 的“初始猜测值”,然后对 \(\theta\) 值不断进行调整,来让 \(J(\theta)\) 逐渐变小,最好是直到我们能够达到一个使 \(J(\theta)\) 最小的 \(\theta\)。具体来说,咱们可以考虑使用梯度下降法(gradient descent algorithm),这个方法就是从某一个 \(\theta\) 的初始值开始,然后逐渐重复更新:
\[ \theta_j := \theta_j - \alpha \frac \partial {\partial\theta_j}J(\theta) \]
(上面的这个更新要同时对应从 \(0\) 到 \(n\) 的所有\(j\) 值进行。)这里的 \(\alpha\) 也称为学习速率。这个算法是很自然的,逐步重复朝向 \(J\) 降低最快的方向移动。
要实现这个算法,咱们需要解决等号右边的导数项。首先来解决只有一组训练样本 \((x, y)\) 的情况,这样就可以忽略掉等号右边对 \(J\) 的求和项目了。公式就简化下面这样:
\[ \begin{aligned} \frac \partial {\partial\theta_j}J(\theta) & = \frac \partial {\partial\theta_j} \frac 12(h_\theta(x)-y)^2\\ & = 2 \cdot\frac 12(h_\theta(x)-y)\cdot \frac \partial {\partial\theta_j} (h_\theta(x)-y) \\ & = (h_\theta(x)-y)\cdot \frac \partial {\partial\theta_j}(\sum^n_{i=0} \theta_ix_i-y) \\ & = (h_\theta(x)-y) x_j \end{aligned} \]
对单个训练样本,更新规则如下所示:
\[ \theta_j := \theta_j + \alpha (y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)} \]
第一种就是下面这个算法:
$ \[\begin{aligned} &\qquad 重复直到收敛 \{ \\ &\qquad\qquad\theta_j := \theta_j + \alpha \sum^m_{i=1}(y^{(i)}-h_\theta (x^{(i)}))x_j^{(i)}\quad(对每个j) \\ &\qquad\} \end{aligned}\]$
读者很容易能证明,在上面这个更新规则中求和项的值就是\(\frac {\partial J(\theta)}{\partial \theta_j}\) (这是因为对 \(J\) 的原始定义)。所以这个更新规则实际上就是对原始的成本函数\(J\)进行简单的梯度下降。这一方法在每一个步长内检查所有整个训练集中的所有样本,也叫做批量梯度下降法(batch gradient descent)。这里要注意,因为梯度下降法容易被局部最小值影响,而我们要解决的这个线性回归的优化问题只能有一个全局的而不是局部的最优解;因此,梯度下降法应该总是收敛到全局最小值(假设学习速率 \(\alpha\) 不设置的过大)。
对咱们之前的房屋数据集进行批量梯度下降来拟合 \(\theta\) ,把房屋价格当作房屋面积的函数来进行预测,我们得到的结果是 \(\theta_0 = 71.27, \theta_1 = 0.1345\)。如果把 \(h_{\theta}(x)\) 作为一个定义域在 \(x\) 上的函数来投影,同时也投上训练集中的已有数据点,会得到下面这幅图:
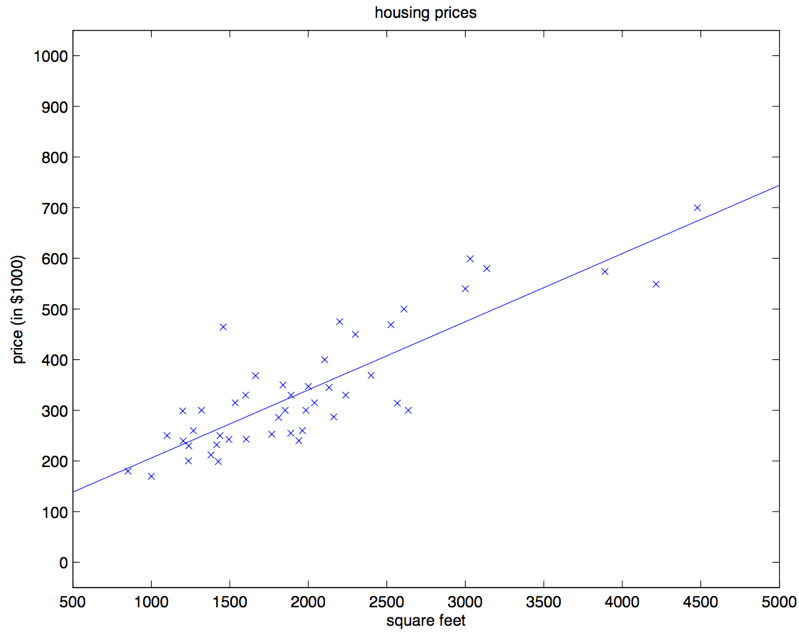
如果在数据集中添加上卧室数目作为输入特征,那么得到的结果就是 \(\theta_0 = 89.60, \theta_1 = 0.1392, \theta_2 = −8.738\)。这个结果就是用批量梯度下降法来获得的。
此外还有另外一种方法能够替代批量梯度下降法,这种方法效果也不错。如下所示:
$ \[\begin{aligned} &\qquad循环:\{ \\ &\qquad\qquad i从1到m,\{ \\ &\qquad\qquad\qquad\theta_j := \theta_j +\alpha(y^{(i)}-h_{\theta}(x^{(i)}))x_j^{(i)} \qquad(对每个 j) \\ &\qquad\qquad\} \\ &\qquad\} \end{aligned}\]$
在这个算法里,我们对整个训练集进行了循环遍历,每次遇到一个训练样本,根据每个单一训练样本的误差梯度来对参数进行更新。这个算法叫做随机梯度下降法(stochastic gradient descent),或者叫增量梯度下降法(incremental gradient descent)。批量梯度下降法要在运行第一步之前先对整个训练集进行扫描遍历,当训练集的规模 \(m\) 变得很大的时候,引起的性能开销就很不划算了;随机梯度下降法就没有这个问题,而是可以立即开始,对查询到的每个样本都进行运算。通常情况下,随机梯度下降法查找到足够接近最低值的 \(\theta\) 的速度要比批量梯度下降法更快一些。(也要注意,也有可能会一直无法收敛(converge)到最小值,这时候 \(\theta\) 会一直在 \(J(\theta)\) 最小值附近震荡;不过通常情况下在最小值附近的这些值大多数其实也足够逼近了,足以满足咱们的精度要求,所以也可以用。)由于这些原因,特别是在训练集很大的情况下,随机梯度下降往往比批量梯度下降更受青睐。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!