PyTorch
1、DataSet
DataSet:提供一种方法去获取数据及其label
使用的数据集为蜜蜂与蚂蚁的图像数据集,分别保存在dataset/train/bees以及dataset/train/ants
DataSet需要通过继承重载才能使用,使用方法如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from torch.utils.data import Datasetfrom PIL import Imageimport osclass MyData (Dataset ):def __init__ (self, root_dir, label_dir ): def __getitem__ (self, index ): open (img_item_path)return img, labeldef __len__ (self ): return len (self.img_path)"dataset/train" "ants" "bees"
2、DataLoader
DataSet就相当于是一整个数据集,而DataLoader是取出其中一部分到神经网络中进行使用。
使用的是torchvision所提供的数据集。DataLoader中的参数分别释义如下:
dataset:我们所使用的数据集,即dataset类型数据
batch_size:一次抓取多少个数据
shuffle:抓取时是否打乱顺序
num_workers:代表创建了多少个worker进程,0表示只有主进程去加载batch数据,1表示有一个worker进程加载batch数据
drop_last:无法整除时,最后剩余的几条数据要不要去除
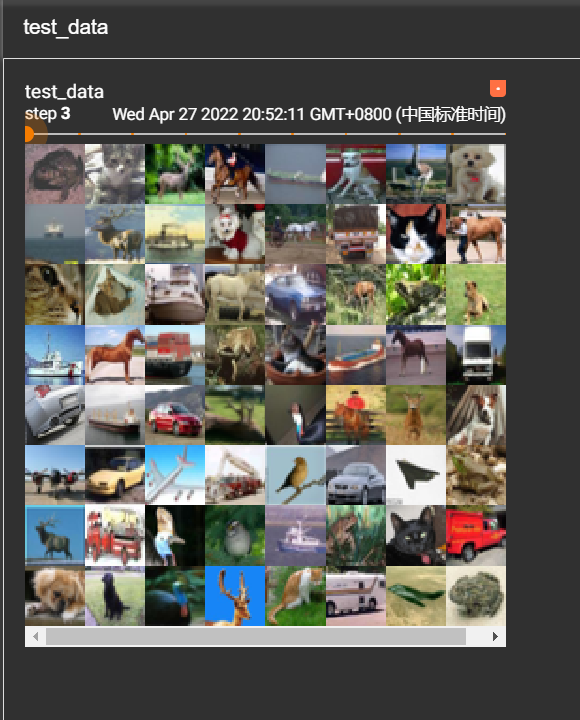
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchvisionfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter"./dataset" , train=False , transform=torchvision.transforms.ToTensor(), download=True )64 , shuffle=True , num_workers=0 , drop_last=False )"dataloader" )0 for data in test_loader:"test_data" , imgs, step)1
最后显示结果如下:
3、TensorBoard
我们可以通过TensorBoard可以查看图像
3.1输出函数图像
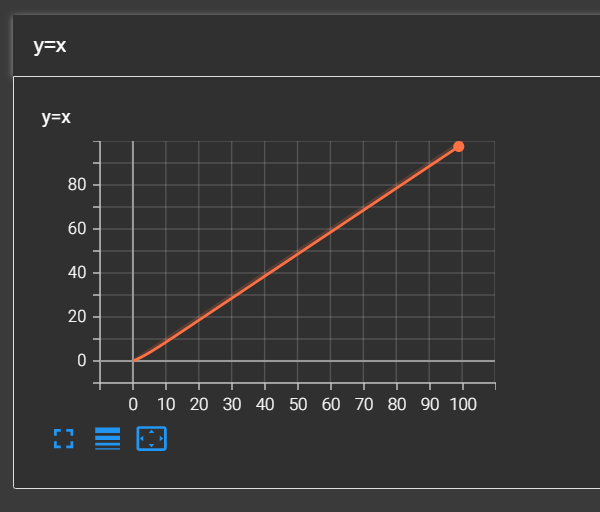
首先我们通过TensorBoard来绘制y=x的图像,我们需要先生成一个实例,随后通过add_scalar()方法来添加,参数分别为名称,y轴的值,x轴的值。
from torch.utils.tensorboard import SummaryWriter"logs" )for i in range (100 ):"y=x" , i, i)
完成后,我们可以通过控制台输入如下指令来观看图像
tensorboard --logdir=logs
这时候我们可以通过6006端口来查看图像,但是如果有很多tensorboard都要查看呢,我们可以选择自定义端口查看,例如我们要选择6007端口来查看,指令如下:
tensorboard --logdir=logs --port=6007
这时候我们就可以看到y=x的图像
如果是y=2x的图像则需要修改代码为:
for i in range (100 ):"y=2x" , 2 *i, i)
3.2输出图片
我们也可以通过TensorBoard来显示我们的图片,通过TensorBoard的add_image()方法,参数分别为名称、图片(需要为tensor类型或者numpy类型)、global_step、类型(因为默认的类型为是(3,H,W)即通道(channel)为3,H为高度,W为宽度),代码如下:
from torch.utils.tensorboard import SummaryWriterimport numpy as npfrom PIL import Image"logs" )"dataset/train/ants/0013035.jpg" open (image_path)"test" , img_array, 1 , dataformats='HWC' )
4、神经网络的基本骨架
基本骨架是通过对nn.Module的继承重写实现的,大体实现如下:
import torchfrom torch import nnclass MyModel (nn.Module):def __init__ (self ):super ().__init__()def forward (self, input ):input + 1 return output1.0 )print (output)
最后我们可以看到控制台输出为:
5、卷积层
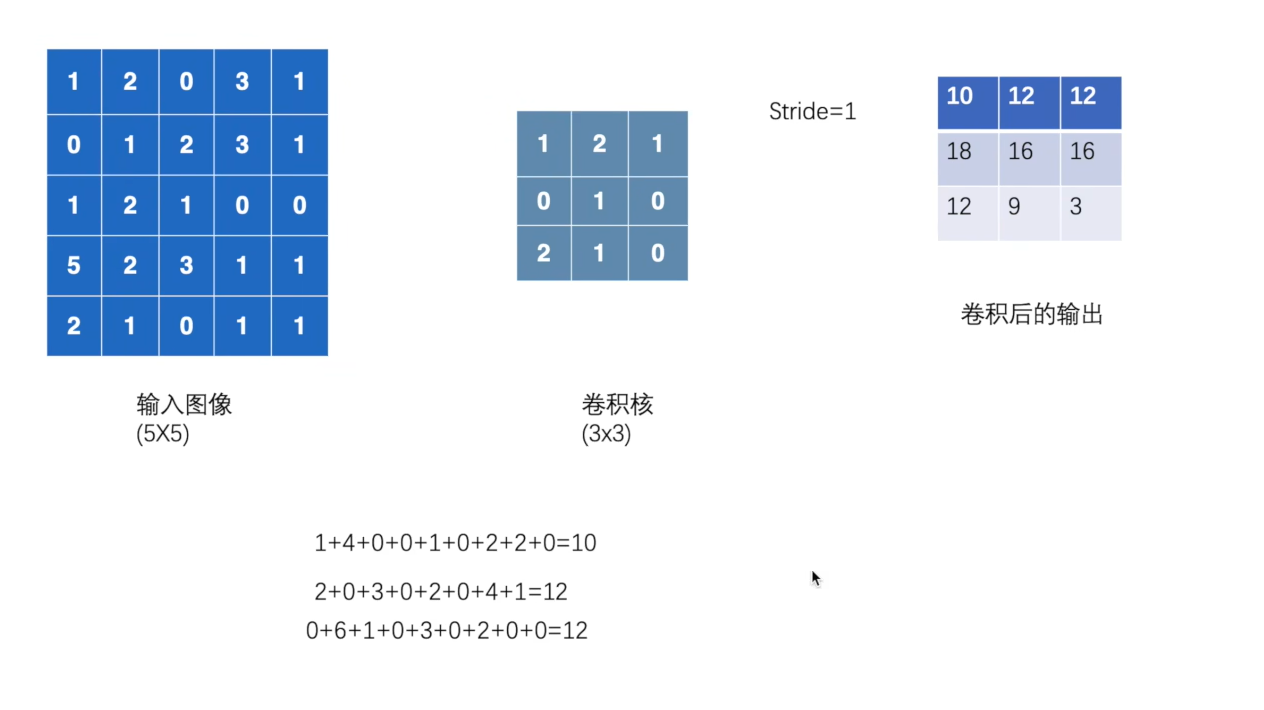
首先对于卷积层的学习,要了解卷积层的使用,我们先使用torch.nn.functional中的方法(一般都是使用torch.nn,其对functional进行了封装,这里是为了了解如何卷积)进行学习,首先要对conv2d的stride参数进行了解,stride时计算卷积时移动的步长,我们可以使用代码来了解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import torchimport torch.nn.functional as Finput = torch.tensor([[1 , 2 , 0 , 3 , 1 ],0 , 1 , 2 , 3 , 1 ],1 , 2 , 1 , 0 , 0 ],5 , 2 , 3 , 1 , 1 ],2 , 1 , 0 , 1 , 1 ]])1 , 2 , 1 ],0 , 1 , 0 ],2 , 1 , 0 ]])input = torch.reshape(input , (1 , 1 , 5 , 5 ))1 , 1 , 3 , 3 ))input , kernel, stride=1 )print (output)input , kernel, stride=2 )print (output2)
输出结果为:
tensor([[[[10, 12, 12],
图示为:
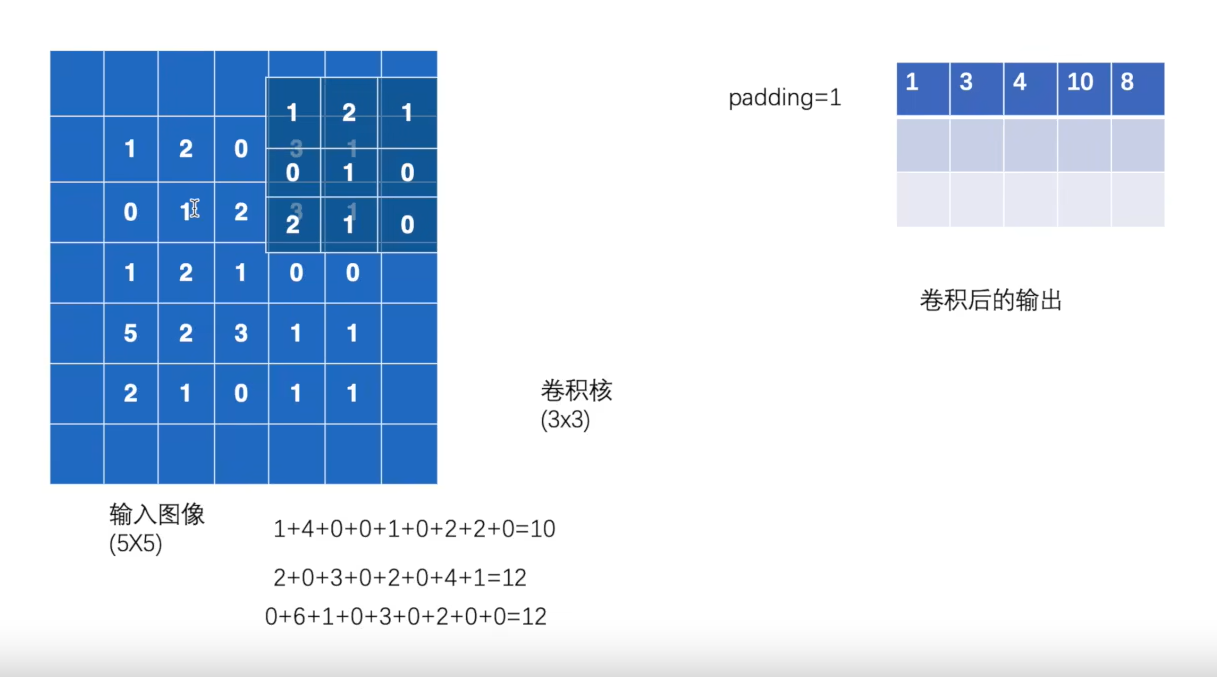
随后我们要学习的是conv2d中的padding参数,它是对输入图像的周围进行填充,并设置填充值:
output3 = F.conv2d(input , kernel, stride=1 , padding=1 )print (output3)
输出结果为:
tensor([[[[ 1, 3, 4, 10, 8],
图示为:
现在对卷积层的知识进行了学习后正式来时学习卷积层是如何搭建的,我们要使用的是torch.nn中的conv2d方法,其方法的参数解释在官方文档中如下:
in_channels (int out_channels (int kernel_size (int or tuple stride (int or tuple ,
optional ) – Stride of the convolution. Default: 1padding (int ,
tuple or str ,
optional ) – Padding added to all four sides of the input.
Default: 0padding_mode (*string**,* optional ) –
'zeros', 'reflect', 'replicate'
or 'circular'. Default: 'zeros'dilation (int or tuple ,
optional ) – Spacing between kernel elements. Default: 1groups (int ,
optional ) – Number of blocked connections from input channels
to output channels. Default: 1bias (bool ,
optional ) – If True, adds a learnable bias to the
output. Default: True
我们简单的对图像进行卷积处理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import torchimport torchvisionfrom torch import nnfrom torch.nn import Conv2dfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter"./dataset" , train=False , transform=torchvision.transforms.ToTensor(),True )64 )class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()3 , out_channels=6 , kernel_size=3 , stride=1 , padding=0 )def forward (self, x ):return x"logs" )0 for data in dataloader:"input" , imgs, step)1 , 3 , 30 , 30 ))"output" , output, step)1
运行结果在tensorboard上显示为:
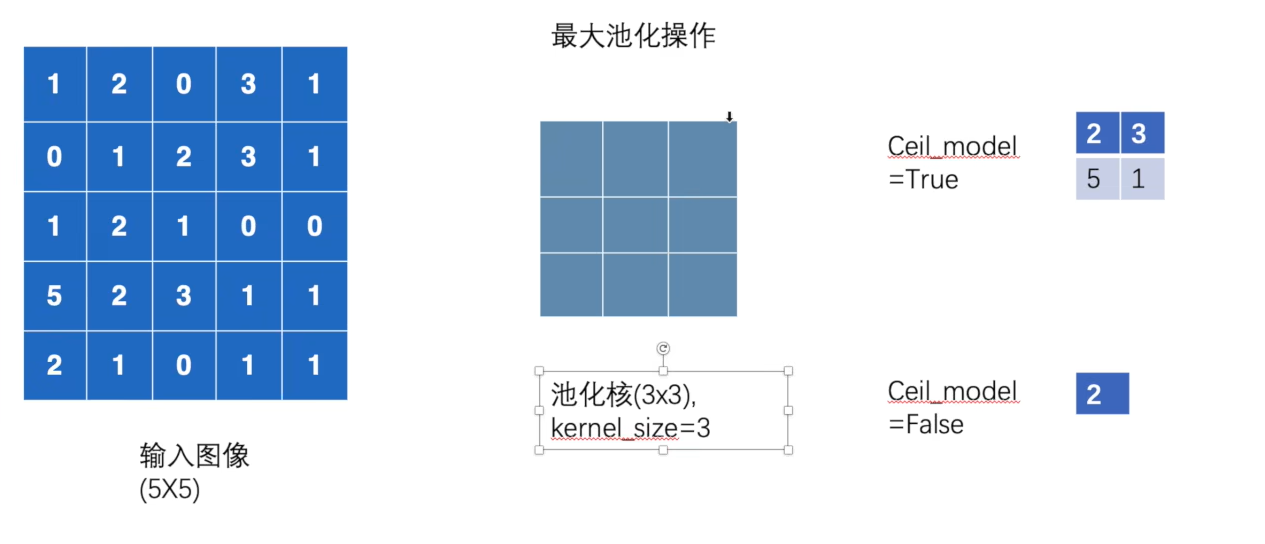
6、池化层
我们要使用的是torch.nn中的MaxPool2d方法,其中参数解释为:
kernel_size – the size of the window to take a max
overstride – the stride of the window. Default value is
kernel_sizepadding – implicit zero padding to be added on both
sidesdilation – a parameter that controls the stride of
elements in the windowreturn_indices – if True, will return
the max indices along with the outputs. Useful for torch.nn.MaxUnpool2dceil_mode – when True, will use ceil instead of
floor to compute the output shape
对于ceil_mode的两种情况如下图示意:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import torchfrom torch import nnfrom torch.nn import MaxPool2dinput = torch.tensor([[1 , 2 , 0 , 3 , 1 ],0 , 1 , 2 , 3 , 1 ],1 , 2 , 1 , 0 , 0 ],5 , 2 , 3 , 1 , 1 ],2 , 1 , 0 , 1 , 1 ]], dtype=torch.float32)input = torch.reshape(input , (-1 , 1 , 5 , 5 ))class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()3 , ceil_mode=True )def forward (self, input ):input )return outputinput )print (output)
运行结果:
tensor([[[[2., 3.],
当我们将ceil_mode修改为False后:
self.maxpool1 = MaxPool2d(kernel_size=3 , ceil_mode=False )
结果为:
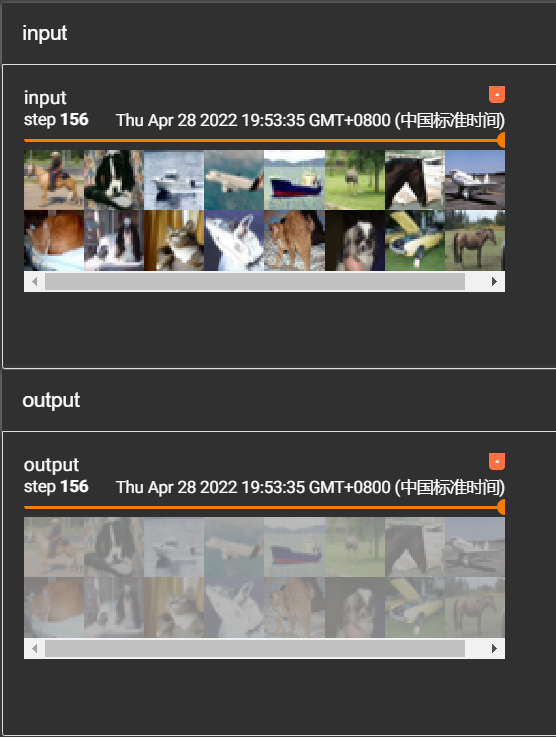
我们可以直观的感受一下最大池化后的结果,我们可以将输入换成我们的数据集,在tensorboard上查看输入输出的差别:
7、非线性激活
首先我们要使用的是torch.nn中的ReLU方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import torchfrom torch import nnfrom torch.nn import ReLUinput = torch.tensor([[1 , -0.5 ],1 , 3 ]])input = torch.reshape(input , (-1 , 1 , 2 , 2 ))class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()def forward (self, input ):input )return outputinput )print (input )print (output)
结果为:
tensor([[[[ 1.0000, -0.5000],
然后我们使用torch.nn中的Sigmoid方法更直观的来查看结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import torchimport torchvisionfrom torch import nnfrom torch.nn import Sigmoidfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriter"./dataset" , train=False , transform=torchvision.transforms.ToTensor(),True )64 )class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()def forward (self, input ):input )return output"logs_sigmoid" )0 for data in dataloader:"input" , imgs, step)"output" , output, step)1
在tensorboard中查看运行结果:
8、线性层 及其他层
主要还是查看官方文档。
9、搭建小实例和Sequential的使用
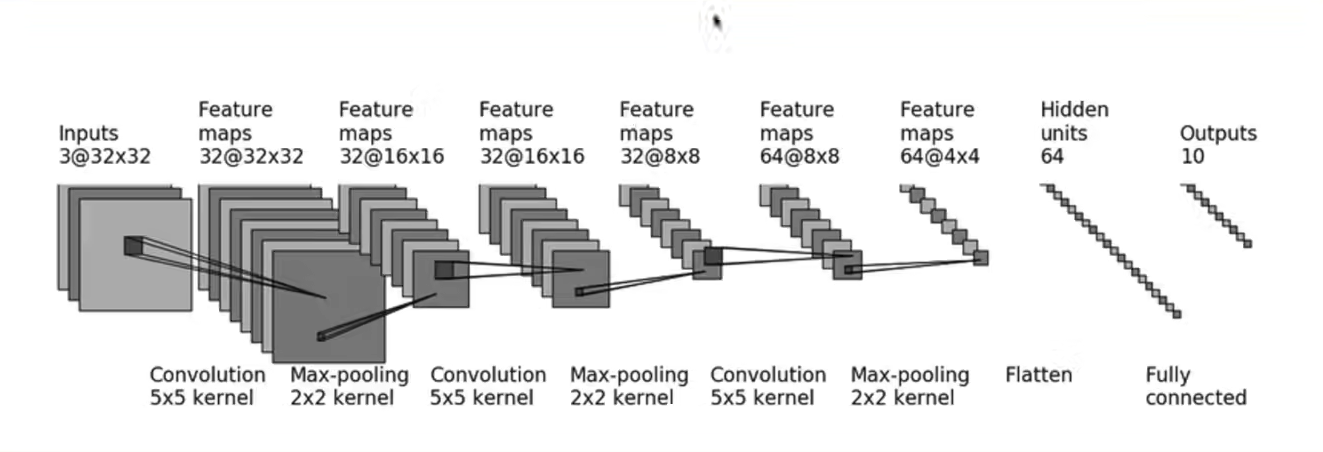
我们使用之前学习过的基础来搭建一个简单的神经网络,例如我们来搭建cifar10的模型,其如下图所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()3 , 32 , 5 , padding=2 )2 )32 , 32 , 5 , padding=2 )2 )32 , 64 , 5 , padding=2 )2 )1024 , 64 )64 , 10 )3 , 32 , 5 , padding=2 )def forward (self, x ):return x
引入了Sequential方法后可以将我们搭建的模型简写出来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MyModel (nn.Module):def __init__ (self ):3 , 32 , 5 , padding=2 ),2 ),32 , 32 , 5 , padding=2 ),2 ),32 , 64 , 5 , padding=2 ),2 ),1024 , 64 ),64 , 10 )def forward (self, x ):return x
10、损失函数与反向传播
我们可以使用torch.nn中的L1Loss以及MSELoss方法来构造损失函数:
input = torch.tensor([1 , 2 , 3 ], dtype=torch.float32)1 , 2 , 5 ], dtype=torch.float32)input = torch.reshape(input , (1 , 1 , 1 , 3 ))1 , 1 , 1 , 3 ))'sum' )input , target)input , target)print (result)print (result_mse)
运行结果为:
我们可以利用交叉熵作为损失函数来进行反向传播,利用backward方法:
myModel = MyModel()for data in dataloader:print ("ok" )
11、优化器
使用torch.optim中的优化器:
myModel = MyModel()0.01 )for epoch in range (20 ):0.0 for data in dataloader:print (runing_loss)
运行结果:
tensor(18666.8984 , grad_fn=<AddBackward0>)16161.6846 , grad_fn=<AddBackward0>)15338.8057 , grad_fn=<AddBackward0>)
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning
rate)的方法。一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。
torch.optim.lr_scheduler.LambdaLR中大部分调整学习率的方法都是根据epoch训练次数
class torch .optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1 )
更新策略: \[
new\_lr=\lambda \times initial\_lr
\] 其中new_lr是得到的新的学习率,initial_lr是初始的学习率,\(\lambda\) 是通过参数lr_lambda和epoch得到的。
参数:
optimizer (Optimizer):要更改学习率的优化器; lr_lambda(function
or list):根据epoch计算\(\lambda\) 的函数;或者是一个list的这样的function,分别计算各个parameter
groups的学习率更新用到的\(\lambda\) ;
last_epoch
(int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
net_1 = model()lambda epoch: 1 /(epoch+1 ))
12、现有网络模型的使用与修改
我们使用torchvision中现有的vgg16模型进行使用:
vgg16_true = torchvison.models.vgg16(pretrained=True )'add_linear' , nn.Linear(1000 , 10 ))6 ] = nn.Linear(4096 , 10 )
13、网络模型的保存与读取
保存方法:
vgg16 = torchvision.models.vgg16(pretrained=False )"vgg16_method1.pth" )"vgg16_method2.pth" )
读取方法:
"vgg16_method1.pth" )False )"vgg16_method1.pth" ))
14、完整的模型训练
model.py:用于保存网络模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import torchfrom torch import nnclass MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()3 , 32 , 5 , 1 , 2 ),2 ),32 , 32 , 5 , 1 , 2 ),2 ),32 , 64 , 5 , 1 , 2 ),2 ),64 * 4 * 4 , 64 ),64 , 10 )def forward (self, x ):return xif __name__ == '__main__' :input = torch.ones((64 , 3 , 32 , 32 ))input )print (output.shape)
train.py:进行网络训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 import torchimport torchvisionfrom torch import nnfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterfrom model import *"./dataset" , train=True , transform=torchvision.transforms.ToTensor(),True )"./dataset" , train=False , transform=torchvision.transforms.ToTensor(),True )len (train_data)len (test_data)64 )64 )0.01 0 0 10 "logs_train" )for i in range (epoch):print ("------第%d轮训练开始------" % (i+1 ))for data in train_dataloader:1 if total_train_step % 100 == 0 :print ("训练次数:{},loss:{}" .format (total_train_step, loss.item()))"train_loss" , loss.item(), total_train_step)eval ()0 0 with torch.no_grad():for data in test_dataloader:1 ) == targets).sum ()print ("整体测试集上的Loss:{}" .format (total_test_loss))print ("整体测试集上的正确率:{}" .format (total_accuracy/test_data_length))"test_loss" , total_test_loss, total_test_step)"test_accuracy" , total_accuracy/test_data_length, total_test_step)1 "myModel_{}.pth" .format (i))print ("模型已保存" )
15、使用GPU训练
方法一
我们需要对网络模型、数据、损失函数进行修改
if torch.cuda.is_available():if torch.cuda.is_available():if torch.cuda.is_available():
方法二
需要在文件最开始定义训练的设备
此时为将设备设置为cpu
"cpu" )
如果要使用gpu需要如下设置:
"cuda" )
如果有多个gpu,可以按照如下选择设置:
"cuda:0" )
16、模型验证套路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 image_path = "./img/dog.png" open (image_path)'RGB' )32 , 32 )),class MyModel (nn.Module):def __init__ (self ):super (MyModel, self).__init__()3 , 32 , 5 , 1 , 2 ),2 ),32 , 32 , 5 , 1 , 2 ),2 ),32 , 64 , 5 , 1 , 2 ),2 ),64 * 4 * 4 , 64 ),64 , 10 )def forward (self, x ):return x"myModel_0.pth" )print (myModel)1 , 3 , 32 , 32 ))eval ()with torch.no_grad():print (output)print (output.argmax(1 ))
输出为:
tensor([[ 0.3308, 0.0307, 0.9064, 0.9474, 0.2715, 0.8123, -0.4077, 0.2044,
可以看到最后预测我们的图片属于第三类
17、LSTM
输入的参数列表包括:
input_size
输入数据的特征维数,通常就是embedding_dim(词向量的维度)
hidden_size LSTM中隐层的维度
num_layers 循环神经网络的层数
bias 用不用偏置,default=True
batch_first
这个要注意,通常我们输入的数据shape=(batch_size,seq_length,embedding_dim),而batch_first默认是False,所以我们的输入数据最好送进LSTM之前将batch_size与seq_length这两个维度调换
dropout 默认是0,代表不用dropout
bidirectional默认是false,代表不用双向LSTM
输入数据包括input,(h_0,c_0):
input就是shape=(seq_length,batch_size,input_size)的张量
h_0是shape=(num_layers*num_directions,batch_size,hidden_size)的张量,它包含了在当前这个batch_size中每个句子的初始隐藏状态。其中num_layers就是LSTM的层数。如果bidirectional=True,num_directions=2,否则就是1,表示只有一个方向。
c_0和h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态。h_0,c_0如果不提供,那么默认是0。
输出数据包括output,(h_n,c_n):
output的shape=(seq_length,batch_size,num_directions*hidden_size),它包含的是LSTM的最后一时间步的输出特征(h_t),t是batch_size中每个句子的长度。
h_n.shape==(num_directions * num_layers,batch,hidden_size)
h_n包含的是句子的最后一个单词(也就是最后一个时间步)的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。
output[-1]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell
state细胞状态才是LSTM中一直隐藏的,记录着信息。
18、LSTMcell
上述的nn.LSTM模块一次构造完若干层的LSTM,但是为了对模型有更加灵活的处nn中还有一个LSTMCell模块,是组成LSTM整个序列计算过程的基本组成单元,也就是进行sequence中一个word的计算。
同时它的参数也就只有3个:输入维度,隐节点数据维度,是否带有偏置。仅提供最基本一个LSTM单元结构,想要完整的进行一个序列的训练的要还要自己编写传播函数把cell间的输入输出连接起来。但是想要自定义不同cell隐节点维度的多层LSTM的话,这个模块还是挺有用的。
19、pad_sequence
sequences :表示输入样本序列,为 list 类型,list
中的元素为 tensor 类型。 tensor 的 size 为 L * F 。其中,L
为单个序列的长度,F 为序列中每个时间步(time
step)特征的个数,根据任务的不同 F 的维度会有所不同。
batch_first :为 True 对应 [batch_size, seq_len,
feature];False 对应[seq_len, batch_size,
feature],从习惯上来讲一般设置为 True 比较符合我们的认知。
padding_value :填充值,默认值为 0 。
说明
主要用来对样本进行填充,填充值一般为 0
。我们在训练网络时,一般会采用一个一个 mini-batch
的方式,将训练样本数据喂给网络。在 PyTorch 里面数据都是以 tensor
的形式存在,一个 mini-batch 实际上就是一个高维的 tensor
,每个序列数据的长度必须相同才能组成一个 tensor 。为了使网络可以处理
mini-batch 形式的数据,就必须对序列样本进行填充,保证一个 mini-batch
里面的数据长度是相同的。
在 PyTorch 里面一般是使用 DataLoader 进行数据加载,返回 mini-batch
形式的数据,再将此数据喂给网络进行训练。我们一般会自定义一个 collate_fn
函数,完成对数据的填充。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import torchfrom torch.utils.data import Dataset, DataLoaderfrom torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pack_sequence,pad_packed_sequenceclass MyData (Dataset ):def __init__ (self, data ):def __len__ (self ):return len (self.data)def __getitem__ (self, idx ):return self.data[idx]def collate_fn (data ):lambda x: len (x), reverse=True )True , padding_value=0 )return data1 ,2 ,3 ,4 ])5 ,6 ,7 ])7 ,8 ])9 ])2 , shuffle=True , collate_fn=collate_fn)iter (data_loader).next ()
运行程序,得到 batch_x 的值:
1 , 2 , 3 , 4 ],9 , 0 , 0 , 0 ]])
从 batch_x 的值可以看出,第二行填充了三个 0
,使其长度和第一行保持一致。
需要说明的是,对于长度不同的序列,使用默认的 collate_fn
函数,不自定义 collate_fn 函数完成对序列的填充,上面的程序就会报错。
20、pack_padded_sequence
参数
input :经过 pad_sequence 处理之后的数据。
lengths :mini-batch中各个序列的实际长度。
batch_first :True 对应 [batch_size, seq_len,
feature] ;
False 对应 [seq_len, batch_size, feature] 。
enforce_sorted :如果是 True
,则输入应该是按长度降序排序的序列。如果是 False
,会在函数内部进行排序。默认值为 True 。
说明
这个 pack 的意思可以理解为压紧或压缩
,因为数据在经过填充之后,会有很多冗余的
padding_value,所以需要压缩一下。
为什么要使用这个函数呢?
RNN 读取数据的方式:网络每次吃进去一组同样时间步 (time step)
的数据,也就是 mini-batch 的所有样本中下标相同的数据,然后获得一个
mini-batch 的输出;再移到下一个时间步 (time step),再读入 mini-batch
中所有该时间步的数据,再输出;直到处理完所有的时间步数据。
第一个时间步:
第二个时间步:
mini-batch 中的 0 只是用来做数据对齐的 padding_value ,如果进行
forward 计算时,把 padding_value
也考虑进去,可能会导致RNN通过了非常多无用的
padding_value,这样不仅浪费计算资源,最后得到的值可能还会存在误差。对于上面的序列
2 的数据,通过 RNN 网络:
实际上从第 2 个时间步开始一直到最后的计算都是多余的,输入都是无效的
padding_value 而已。
从上面的分析可以看出,为了使 RNN 可以高效的读取数据进行训练,就需要在
pad 之后再使用 pack_padded_sequence 对数据进行处理。
需要注意的是,默认条件下,我们必须把输入数据按照序列长度从大到小排列后才能送入
pack_padded_sequence ,否则会报错。
示例
只需要将上面的例子中的 collate_fn
函数稍作修改即可,其余部分保持不变。
def collate_fn (data ):lambda x: len (x), reverse=True )0 ) for s in data] True ) True )return data
输出:
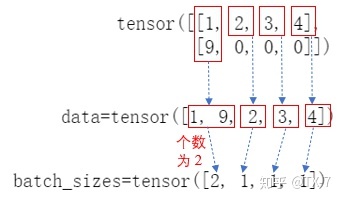
1 , 9 , 2 , 3 , 4 ]), 2 , 1 , 1 , 1 ]), None , unsorted_indices=None )
可以看出,输出返回一个 PackedSequence 对象,它主要包含两部分:data 和
batch_sizes 。
填充值 0 就被跳过了。batch_size
中的值,实际上就是告诉网络每个时间步需要吃进去多少数据。
如果仔细看,其实输出的 PackedSequence 对象还包含两个部分
sorted_indices 和unsorted_indices 。前面说到 pack_padded_sequence
还有一个参数 enforce_sorted ,如果是 True
,则输入应该是按长度降序排序的序列。如果是 False
,会在函数内部进行排序。默认值为 True 。也就是说在输入
pack_padded_sequence 前,我们也可以不对数据进行排序。
现在我们将 enforce_sorted 设置为 False
,且输入数据不预先进行排序。
data = [torch.tensor([9 ]), 1 ,2 ,3 ,4 ]),5 ,6 ])]0 ) for s in data]True ) True , enforce_sorted=False )
输出:
PackedSequence(data=tensor([1 , 5 , 9 , 2 , 6 , 3 , 4 ]), 3 , 2 , 1 , 1 ]), 1 , 2 , 0 ]), 2 , 0 , 1 ]))
sorted_indices = tensor([1, 2, 0],表示排序之后的结果与原始 data 中的
tensor 的下标对应关系。1 表示原始 data 中 第 1
行最长,排序之后排在最前面,其次是第 2 行、第 0 行。
假设排序之后的结果为:
sort_data = [torch.tensor([1 ,2 ,3 ,4 ]),5 ,6 ])9 ]),
unsorted_indices = tensor([2, 0, 1],表示未排序前结果。2 表示
sort_data 的第 2 行对应 data 中第 0 行;0 表示 sort_data 的第 0 行对应
data 中的第 1 行;1 表示 sort_data 的第 1 行对应 data 中的第 2 行。
21、pack_sequence
参数
sequences :输入样本序列,为 list 类型,list
中的元素为 tensor ;tensor 的 size 为 L * F,其中,L 为单个序列的长度,F
为序列中每个时间步(time step)特征的个数,根据任务的不同 F
的维度会有所不同。
enforce_sorted :如果是 True
,则输入应该是按长度降序排序的序列。如果是 False
,会在函数内部进行排序。默认值为 True 。
说明
我们看看 PyTorch 中的源码:
def pack_sequence (sequences, enforce_sorted=True ): 0 ) for v in sequences]) return pack_padded_sequence(pad_sequence(sequences),lengths,enforce_sorted=enforce_sorted)
可以看出 pack_sequence 实际上就是对 pad_sequence 和
pack_padded_sequence
操作的一个封装。通过一个函数完成了两步才能完成的工作。
示例
前面的 collate_fn 函数可以进一步修改为:
def collate_fn (data ):lambda x: len (x), reverse=True )return data
输出结果与前面相同:
1 , 9 , 2 , 3 , 4 ]), 2 , 1 , 1 , 1 ]), None , unsorted_indices=None )
22、pad_packed_sequence
参数
sequences :PackedSequence 对象,将要被填充的 batch
;
batch_first :一般设置为 True,返回的数据格式为
[batch_size, seq_len, feature] ;
padding_value :填充值;
total_length :如果不是None,输出将被填充到长度:total_length。
说明
如果在喂给网络数据的时候,用了 pack_sequence 进行打包,pytorch 的 RNN
也会把输出 out 打包成一个 PackedSequence 对象。
这个函数实际上是 pack_padded_sequence
函数的逆向操作。就是把压紧的序列再填充回来。
为啥要填充回来呢?我的理解是,在 collate_fn 函数里面通常也会调用
pad_sequence 对 label 进行填充,RNN 的输出结果为了和 label
对齐,需要将压紧的序列再填充回来,方便后续的计算。
示例
需要说明的是,下面的程序中,为了产生符合 LSTM 输入格式 [batch_size,
seq_len, feature] 的数据,使用了函数 unsqueeze 进行升维处理。其中,
batch_size 是样本数 ,seq_len
是序列长度 ,feature 是特征数 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class MyData (Dataset ):def __init__ (self, data ):def __len__ (self ):return len (self.data)def __getitem__ (self, idx ):return self.data[idx]def collate_fn (data ):lambda x: len (x), reverse=True )0 ) for s in data]True ).float () 1 )True )return data1 ,2 ,3 ,4 ])5 ,6 ,7 ])7 ,8 ])9 ])2 , shuffle=True , collate_fn=collate_fn)iter (data_loader).next ()1 , 4 , 1 , batch_first=True )1 , 2 , 4 ).float ()1 , 2 , 4 ).float ()
得到 out 的结果如下,是一个 PackedSequence 类型的对象,与前面调用
pack_padded_sequence 得到的结果类型相同。
1.3302e-04 , 5.7754e-02 , 4.3181e-02 , 6.4226e-02 ],2.8673e-02 , 3.9089e-02 , -2.6875e-03 , 4.2686e-03 ],1.0216e-01 , 2.5236e-02 , -1.2230e-01 , 5.1524e-02 ],1.6211e-01 , 2.1079e-02 , -1.5849e-01 , 5.2800e-02 ],1.5774e-01 , 2.6749e-02 , -1.3333e-01 , 4.7894e-02 ]],2 , 1 , 1 , 1 ]), None , unsorted_indices=None )
对 out 调用 pad_packed_sequence 进行填充:
out_pad, out_len = pad_packed_sequence(out, batch_first=True )
out_pad 和 out_len 的结果如下:
1.3302e-04 , 5.7754e-02 , 4.3181e-02 , 6.4226e-02 ],1.0216e-01 , 2.5236e-02 , -1.2230e-01 , 5.1524e-02 ],1.6211e-01 , 2.1079e-02 , -1.5849e-01 , 5.2800e-02 ],1.5774e-01 , 2.6749e-02 , -1.3333e-01 , 4.7894e-02 ]],2.8673e-02 , 3.9089e-02 , -2.6875e-03 , 4.2686e-03 ],0.0000e+00 , 0.0000e+00 , 0.0000e+00 , 0.0000e+00 ],0.0000e+00 , 0.0000e+00 , 0.0000e+00 , 0.0000e+00 ],0.0000e+00 , 0.0000e+00 , 0.0000e+00 , 0.0000e+00 ]]],4 , 1 ])
再回想下我们调用 pad_sequence 填充之后的输入:
1 , 2 , 3 , 4 ],9 , 0 , 0 , 0 ]])
这个 out_pad 结果其实就和我们填充之后的输入对应起来了。
22、cat
出了两个张量A和B,分别是2行3列,4行3列。即他们都是2维张量。因为只有两维,这样在用torch.cat拼接的时候就有两种拼接方式:按行拼接和按列拼接。即所谓的维数0和维数1.
C=torch.cat((A,B),0)就表示按维数0(行)拼接A和B,也就是竖着拼接,A上B下。此时需要注意:列数必须一致,即维数1数值要相同,这里都是3列,方能列对齐。拼接后的C的第0维是两个维数0数值和,即2+4=6
C=torch.cat((A,B),1)就表示按维数1(列)拼接A和B,也就是横着拼接,A左B右。此时需要注意:行数必须一致,即维数0数值要相同,这里都是2行,方能行对齐。拼接后的C的第1维是两个维数1数值和,即3+4=7
23、torch.split
torch.split(tensor, split_size_or_sections, dim=0)
torch.split()作用将tensor分成块结构。
参数:
tesnor:input,待分输入
split_size_or_sections:需要切分的大小(int or list )
dim:切分维度
output:切分后块结构 <class 'tuple'>
当split_size_or_sections为int 时,tenor结构和split_size_or_sections,正好匹配,那么ouput就是大小相同的块结构。如果按照split_size_or_sections结构,tensor不够了,那么就把剩下的那部分做一个块处理。
当split_size_or_sections
为list 时,那么tensor结构会一共切分成len(list)这么多的小块,每个小块中的大小按照list中的大小决定,其中list中的数字总和应等于该维度的大小,否则会报错(注意这里与split_size_or_sections为int时的情况不同)。
24、torch.squeeze和torch.unsqueeze
⼀、先看torch.squeeze()
这个函数主要对数据的维度进⾏压缩,去掉维数为1的的维度,⽐如是⼀⾏或者⼀列这种,⼀个⼀⾏三列(1,3)的数去掉第⼀个维数为⼀的维度之后就变成(3)⾏。
1.squeeze(a)就是将a中所有为1的维度删掉。不为1的维度没有影响。
2.a.squeeze(N) 就是去掉a中指定的维数为⼀的维度。
3.还有⼀种形式就是b=torch.squeeze(a,N)
a中去掉指定的维数N为⼀的维度。
⼆、再看torch.unsqueeze()这个函数主要是对数据维度进⾏扩充。
1.给指定位置加上维数为⼀的维度,⽐如原本有个三⾏的数据(3),在0的位置加了⼀维就变成⼀⾏三列(1,3)。a.unsqueeze(N)
就是在a中指定位置N加上⼀个维数为1的维度。
2.还有⼀种形式就是b=torch.unsqueeze(a,N)
a就是在a中指定位置N加上⼀个维数为1的维度
25、nn.Embedding
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None,max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None)
其为一个简单的存储固定大小的词典的嵌入向量的查找表,意思就是说,给一个编号,嵌入层就能返回这个编号对应的嵌入向量,嵌入向量反映了各个编号代表的符号之间的语义关系。
输入为一个编号列表,输出为对应的符号嵌入向量列表。
参数解释
num_embeddings (python:int) –
词典的大小尺寸,比如总共出现5000个词,那就输入5000。此时index为(0-4999)
embedding_dim (python:int) –
嵌入向量的维度,即用多少维来表示一个符号。
padding_idx (python:int, optional) –
填充id,比如,输入长度为100,但是每次的句子长度并不一样,后面就需要用统一的数字填充,而这里就是指定这个数字,这样,网络在遇到填充id时,就不会计算其与其它符号的相关性。(初始化为0)
max_norm (python:float, optional) –
最大范数,如果嵌入向量的范数超过了这个界限,就要进行再归一化。
norm_type (python:float, optional) –
指定利用什么范数计算,并用于对比max_norm,默认为2范数。
scale_grad_by_freq (boolean, optional) –
根据单词在mini-batch中出现的频率,对梯度进行放缩。默认为False.
sparse (bool, optional) –
若为True,则与权重矩阵相关的梯度转变为稀疏张量。
26、torch.bmm
计算两个torch的矩阵乘法
函数定义:
def bmm(self: Tensor,mat2: Tensor,*,out: Optional[Tensor] = None) -> Tensor
函数的传入参数很简单,两个三维矩阵 而已,只是要注意这两个矩阵的shape有一些要求:
res = torch.bmm(ma, mb)
ma: [a, b, c]
mb: [a, c, d]
27、DP训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import torchfrom torch.nn.parallel import DataParallelfrom torchvision import datasets, transformsimport torchvisionfrom tqdm import tqdm0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 ] 64 "./data/" ,True ,True )"./data/" ,False )len (device_ids),True ,2 )len (device_ids),True ,2 )class Model (torch.nn.Module):def __init__ (self ):super (Model, self).__init__()1 , 64 , kernel_size=3 , stride=1 , padding=1 ),64 , 128 , kernel_size=3 , stride=1 , padding=1 ),2 , kernel_size=2 ),14 * 14 * 128 , 1024 ),0.5 ),1024 , 10 )def forward (self, x ):1 , 14 * 14 * 128 )return x50 for epoch in range (n_epochs):0.0 0 print ("Epoch {}/{}" .format (epoch, n_epochs))for data in tqdm(data_loader_train):0 for data in data_loader_test:max (outputs.data, 1 )sum (pred == y_test.data)"model_parameter.pth" )
28、DDP训练
29、warm up和余弦退火
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 import mathimport torchfrom torch.optim import lr_scheduler as lr_schedulerimport torch.nn as nnfrom tqdm import tqdmfrom torch.utils.data import DataLoader, Datasetimport matplotlib.pyplot as pltimport numpy as npdef warm_up_cosine_lr_scheduler (optimizer, epochs=100 , warm_up_epochs=10 , eta_min=1e-9 ):if warm_up_epochs <= 0 :else :lambda epoch: eta_min + (if epoch <= warm_up_epochs else 0.5 * (1 )return schedulerclass WarmupCosineLR (lr_scheduler._LRScheduler):def __init__ (self, optimizer, lr_min, lr_max, warm_up=0 , T_max=10 , start_ratio=0.1 ):0 super ().__init__(optimizer, -1 )def get_lr (self ):if (self.warm_up == 0 ) & (self.cur == 0 ):elif (self.warm_up != 0 ) & (self.cur <= self.warm_up):if self.cur == 0 :else :else :0.5 * \1 )1 return [lr for base_lr in self.base_lrs]class TestDataset (Dataset ):def __init__ (self, num ):super ().__init__()for i in range (num):3 , 32 , 32 )16 , 32 , 32 )def __len__ (self ):return len (self.images)def __getitem__ (self, item ):return image, label10 )64 , shuffle=True )class Net (nn.Module):def __init__ (self ):super (Net, self).__init__()3 , 16 , 3 , 1 , 1 )def forward (self, x ):return self.conv(x)100 2 0.1 10 100 1e-3 , momentum=5e-4 , nesterov=True )1e-9 , 1e-3 , warmup, epochs, 0.1 )for epoch in tqdm(range (epochs)):for i, (inputs, targets) in enumerate (train_loader):'param_groups' ][0 ]['lr' ])10 , 6 ))'r' )0 , lrs[0 ], str (lrs[0 ]))10 , lrs[10 ], str (lrs[10 ]))1 ], str (lrs[-1 ]))
30、混合精度训练
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import torchfrom torch import nn, optimfrom torchvision import models, datasets, transformsfrom torch.utils.data import DataLoaderfrom torch.cuda.amp import autocast, GradScalerTrue )10 224 ),0.485 , 0.456 , 0.406 ], std=[0.229 , 0.224 , 0.225 ]),'path/to/cifar10' , train=True , download=True , transform=transform)32 , shuffle=True , num_workers=4 )0.001 , momentum=0.9 )5 , gamma=0.1 ) 10 for epoch in range (num_epochs):for inputs, labels in dataloader:with autocast():