第一讲-NLP介绍与词向量初步
1 自然语言与词汇含义
1.1 如何在计算机里表达词的意义
要使用计算机处理文本词汇,一种处理方式是WordNet:即构建一个包含同义词集和上位词(“is a”关系)的列表的辞典。英文当中确实有这样一个 wordnet,我们在安装完NLTK工具库和下载数据包后可以使用,对应的 python 代码如下:
1 | |
运行结果如下:
1 | |
1 | |
1.2 WordNet的问题
作为一个资源很好,但忽略了细微差别。例如“proficient”被列为“good”的同义词,这只是在一些上下文中是正确的。
缺少单词的新含义,难以持续更新。
是主观的,需要人们来创造和调整,无法计算单词相似度。
1.3 文本(词汇)的离散表征
在传统的自然语言处理中,我们会对文本做离散表征,把词语看作离散的符号:例如hotel、conference、motel等。
one-hot vector是只有一个1,其余全为零的稀疏向量,单词可以通过one-hot vector来表示: \[ \text { motel }=\left[\begin{array}{lllllllllllllll} 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 \end{array}\right] \]
\[ \text { hotel }=\left[\begin{array}{lllllllllllllll} 0 & 0 & 0 & 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \end{array}\right] \]
在one-hot vector中向量维度 = 词汇量(如500,000)
1.4 离散表征的问题
在上述的独热向量离散表征里,所有词向量是正交的,这是一个很大的问题。对于独热向量,没有关于相似性概念,并且向量维度过大。
对于上述问题有一些解决思路:
- ① 使用类似WordNet的工具中的列表,获得相似度,但会因不够完整而失败
- ② 通过大量数据学习词向量本身相似性,获得更精确的稠密词向量编码
1.5 基于上下文的词汇表征
近年来在深度学习中比较有效的方式是基于上下文的词汇表征。它的核心想法是:一个单词的意思是由经常出现在它附近的单词给出的
这是现代统计NLP最成功的理念之一,总体思路有点物以类聚,人以群分的感觉。
- 当一个单词\(w\)出现在文本中时,它的上下文是出现在其附近的一组单词(在一个固定大小的窗口中)
- 基于海量数据,使用\(w\)的许多上下文来构建\(w\)的表示
2 Word Vectors
2.1 词向量表示
Word2vec (Mikolov et al. 2013)是一个学习词向量表征的框架。
- 核心思路如下:
- 基于海量文本语料库构建
- 词汇表中的每个单词都由一个向量表示(学习完成后会固定)
- 对应语料库文本中的每个位置\(t\),有一个中心词\(c\)和一些上下文(“外部”)单词\(o\)
- 使用\(c\)和\(o\)的词向量来计算概率\(P(o|c)\),即给定中心词推断上下文词汇的概率(反之亦然)
- 不断调整词向量来最大化这个概率
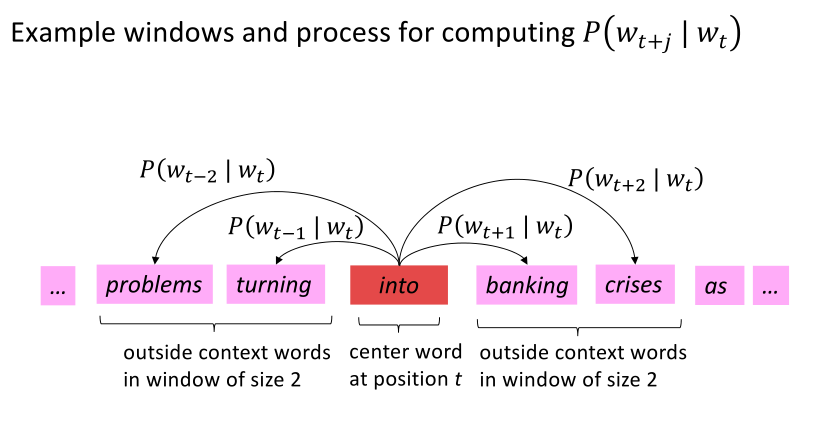
3 Word2vec 目标函数
3.1 似然函数
对于每个位置t = 1, … , T, 在大小为\(m\)的固定窗口内预测上下文单词,给定中心词\(w_j\),似然函数可以表示为: \[ Likelihood = L(\theta) = \prod_{t=1}^{T} \prod_{\substack{-m \leq j \leq m \\ j \neq 0}}P(w_{t+j}|w_t;\theta) \]
上述公式中,\(\theta\)为模型包含的所有待优化权重变量
3.2 目标函数
对应上述似然函数的目标函\(J(\theta)\)可以取作(平均)负对数似然: \[ Likelihood=-\frac1T \log L(\theta)=-\frac1T \sum_{t=1}^{T} \sum_{\substack{-m \leq j \leq m \\ j \neq 0}} \log P(w_{t+j}|w_t;\theta) \]
注意:
- 目标函数\(J(\theta)\)有时也被称为“代价函数”或“损失函数”
- 最小化目标函数与最大化似然函数(预测概率/精度)两者等价
得到目标函数后,我们希望最小化目标函数,那我们如何计算\(P(w_{t+j}|w_t;\theta)\)?
对于每个词\(w\)都会用两个向量:
- 当\(w\)是中心词时,我们标记词向量为\(v_w\)
- 当\(w\)是上下文词时,我们标记词向量为\(u_w\)
则对于一个中心词\(c\)和一个上下文词\(o\),我们有如下概率计算公式 \[ P(o \mid c)=\frac{\exp \left(u_{o}^{T} v_{c}\right)}{\sum_{w \in V} \exp \left(u_{w}^{T} v_{c}\right)} \]
- 对\(u_o^Tv_c\)是将两个向量进行点积,为了计算两个词向量的相似度,点积的结果越大,那么相似度越大。
- 模型的训练正是为了使得具有相似上下文的单词,具有相似的向量
- 点积是计算相似性的一种简单方法,在注意力机制中常使用点积计算 Score
4 Word2vec预测函数
这也就是softmax function(\(R^n\Rightarrow(0,1)^n\))的一个例子,将\(x_i\)映射到\(p_i\): \[ \operatorname{softmax}\left(x_{i}\right)=\frac{\exp \left(x_{i}\right)}{\sum_{j=1}^{n} \exp \left(x_{j}\right)}=p_{i} \] 为了训练模型,我们就要找出参数最小化loss函数
Recall:\(\theta\)通过一个长向量来代表所有的模型参数
在我们的例子中,对于d维向量和V个单词,我们得出:
\[ \theta=\left[\begin{array}{l} v_{\text {aardvark }} \\ v_{a} \\ \vdots \\ v_{z e b r a} \\ u_{a a r d v a r k} \\ u_{a} \\ \vdots \\ u_{z e b r a} \end{array}\right] \in \mathbb{R}^{2 d V} \]
所以我们每个单词有两个向量
我们就需要计算所有向量的梯度进行梯度下降算法来最小化loss函数
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!