NLP-Assignment2
Assignment2
解答:理解词向量(23分)
我们先快速回顾一下word2vec算法,它的核心思想是“一个词的含义可以由它周围的词来表示”。具体来说,我们有一个中心词(center word) c,和这个词 c 周围上下文构成的窗口,这个窗口内的除了 c 之外的词叫做外围词(outside words)。比如下图中,中心词是“banking”,窗口大小为2,所以上下文窗口是:“turning”、”into“、”crises“和”as“。
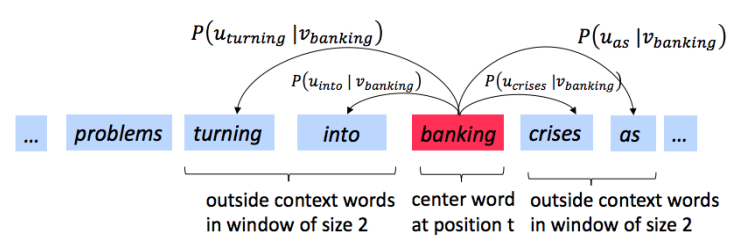
Skip-gram模型(word2vec比较常用的一种实现,另一种是cbow)目的是学习概率分布 \(𝑃(𝑂|𝐶)\)。这样一来,就能计算给定的一个词 \(o\) 和词 \(c\) 的概率 \(𝑃(𝑂=𝑜|𝐶=𝑐)\)(即,在已知词 \(c\) 出现的情况下,词 \(o\) 出现的概率), 其中\(c\) 是中心词,\(o\) 是窗口中非中心的外围词。
在word2vec中,这个条件概率分布是通过计算向量点积(dot-products),再应用naive-softmax函数得到的: \[ P(O=o \mid C=c)=\frac{\exp \left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)}{\sum_{w \in \operatorname{Vocab}} \exp \left(\boldsymbol{u}_{w}^{\top} \boldsymbol{v}_{c}\right)} \]
这里,\(𝑢_o\)向量代表外围词,\(v_c\)向量代表中心词。为了包含这些向量,我们有两个矩阵 \(𝑈\) 和 \(𝑉\) 。 \(𝑈\) 的列是外围词, \(V\) 的列是中心词,这两矩阵都有所有词\(w \in Vocabulary\)的表示 。
对于词 \(c\) 和词 \(o\),损失函数为对数几率: \[ \boldsymbol{J}_{naive-softmax}(v_c, o, \boldsymbol{U}) = -log P(O=o \mid C=c) \]
可以从交叉熵的角度看这个损失函数。真实值为 \(y\) ,是一个独热向量,预测值 \(\hat{y}\) 计算得到。具体来说, \(y\) 如果是第k个单词,那么它的第k维为1,其余维都是0,而 \(\hat{y}\) 的第k维表示这是第k个词的概率大小。
问题(a) (3分)
证明公式(2)给出的naive-softmax的损失函数,和 \(y\) 与 \(\hat{y}\) 的交叉熵损失函数是一样的,均如下所示(答案控制在一行)
\[-\sum_{w \in V o c a b} y_{w} \log \left(\hat{y}_{w}\right)=-\log \left(\hat{y}_{o}\right)\]
答:因为除了 \(o\) 之外的词都不在窗口内,所以只有词 \(o\) 对损失函数有贡献
问题(b) (5分)
计算损失函数 \(\boldsymbol{J}_{naive-softmax}(v_c, o, \boldsymbol{U})\) 对中心词 \(v_c\) 的偏导数,用 \(y\) ,\(\hat{y}\)和 \(𝑈\) 来表示。
答: \[ \begin{aligned} J_{\text {naive-softmax} }\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right) &=-\log P(O=o | C=c) \\ &= -\log \frac{\exp \left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)} {\sum_{w \in \operatorname{Vocab} } \exp \left(\boldsymbol{u}_{\boldsymbol{w} }^{\top} \boldsymbol{v}_{c}\right)} \\ &= - {u}_{o}^{\top}{v}_{c} + \log \sum_{w \in \operatorname{Vocab} } \exp \left(\boldsymbol{u}_{\boldsymbol{w} }^{\top} \boldsymbol{v}_{c}\right) \end{aligned} \]
\[ \begin{aligned} \frac{\partial J_{\text {naive-softmax} }\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right)}{\partial v_c} &= -u_o + \sum_{o \in \operatorname{Vocab} }\frac{\exp(u_o^\top v_c)}{\sum_{w \in \operatorname{Vocab} } \exp \left(\boldsymbol{u}_{\boldsymbol{w} }^{\top} \boldsymbol{v}_{c}\right)} \frac{\partial (u_o^\top v_c)}{\partial v_c}\\ &=-u_o + \sum_{o \in \operatorname{Vocab} } P(O=o | C=c) u_o \\ &=- U y + U \hat y \\ &= U(\hat y - y) \end{aligned} \]
问题(c) (5分)
计算损失函数 \(\boldsymbol{J}_{naive-softmax}(v_c, o, \boldsymbol{U})\) 对上下文窗口内的词 \(w\) 的偏导数,考虑两种情况,即 \(w\) 是外围词 \(o\),和 \(w\) 不是 \(o\),用 \(y\) ,\(\hat{y}\)和 \(v_c\) 来表示。
答: \[ \begin{aligned} \frac{\partial J_{\text {naive-softmax} }\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right)}{\partial u_w} &= -v_c 1_{\lbrace w=o \rbrace } + \frac{\exp(u_w^\top v_c)}{\sum_{w \in \operatorname{Vocab} } \exp \left(\boldsymbol{u}_{\boldsymbol{w} }^{\top} \boldsymbol{v}_{c}\right)} \frac{\partial (u_w^\top v_c)}{\partial u_w}\\ &=-v_c 1_{\lbrace w=o \rbrace } + P(O=w | C=c) v_c \\ &=v_c( \hat y_w - y_w) \end{aligned} \]
问题(d) (3分)
sigmoid函数如公式所示 \[ \sigma(\boldsymbol{x})=\frac{1}{1+e^{-\boldsymbol{x}}}=\frac{e^{\boldsymbol{x}}}{e^{\boldsymbol{x}}+1} \] 请计算出它对于 \(x\) 的导数, \(x\) 是一个向量
答:
计算雅克比矩阵可得 \[ \begin{aligned} \frac{\partial \sigma(x_i )}{\partial x_j } &= \sigma (x_i) (1 -\sigma(x_i)) 1_{\lbrace i=j\rbrace } \end{aligned} \] 所以有 \[ \frac{\partial \sigma(x)}{\partial x} =\text{diag}(\sigma(x) (1- \sigma(x))) \]
问题(e) (4分)
现在我们考虑负采样的损失函数。假设有K个负样本,表示为\(w_1, w_2, …, w_K\),它们对应的向量为 \(u_1, u_2, …, u_K\),外围词 \(o \not\in {w_1, w_2, …, w_K}\),则外围词 \(o\) 在中心词是 \(c\) 时产生的损失函数如公式所示。 \[ \boldsymbol{J}_{\text {neg-sample }}\left(\boldsymbol{v}_{c}, o, \boldsymbol{U}\right)=-\log \left(\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)-\sum_{k=1}^{K} \log \left(\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right) \] 根据该损失函数,重新计算问题(b)、问题(c)的偏导数,用 \(\boldsymbol{u}_o\),\(\boldsymbol{v}_c\),\(\boldsymbol{u}_k\) 来表示。
完成计算后,简要解释为什么这个损失函数比naive-softmax效率更高。
注意:你可以用问题(d)的答案来帮助你计算导数
答: \[ \begin{aligned} \frac{\partial J_{\text {neg-sample} }\left(v_{c}, o, U\right)}{\partial v_c} &=-\frac{\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\left(1- \sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)}{\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)}u _o -\sum_{k=1}^K \frac{\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\left(1- \sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)} {\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)}(-u_k)\\ &= -\left(1- \sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)u_o + \sum_{k=1}^K \left(1- \sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)u_k\\ \frac{\partial J_{\text {neg-sample} }\left(v_{c}, o, U\right)}{\partial u_o} &=-\frac{\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\left(1- \sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)}{\sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)}v _c \\ &= -\left(1- \sigma\left(\boldsymbol{u}_{o}^{\top} \boldsymbol{v}_{c}\right)\right)v_c \\ \frac{\partial J_{\text {neg-sample} }\left(v_{c}, o, U\right)}{\partial u_k} &= - \frac{\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\left(1- \sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)} {\sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)}(-v_c)\\ &= \left(1- \sigma\left(-\boldsymbol{u}_{k}^{\top} \boldsymbol{v}_{c}\right)\right)v_c \end{aligned} \]
原始的损失函数中需要求指数和,很容易溢出,负采样的损失函数能很好地规避这个问题。
词库从 𝑉𝑜𝑐𝑎𝑏 变成了K+1个词
在求内层导数的时候用了sigmoid函数
问题(f) (3分)
假设中心词是 \(c = w_t\),上下文窗口是\([w_{t-m}, …, w_{t-1}, w_t, w_{t+1}, …, w_{t+m}]\),\(m\) 是窗口大小,回顾skip-gram的word2vec实现,在该窗口下的总损失函数是: \[ \boldsymbol{J}_{\text {skip-gram }}\left(\boldsymbol{v}_{c}, w_{t-m}, \ldots w_{t+m}, \boldsymbol{U}\right)=\sum_{-m \leq j \leq m \atop j \neq 0} \boldsymbol{J}\left(\boldsymbol{v}_{c}, w_{t+j}, \boldsymbol{U}\right) \] 这里,\(\boldsymbol{J}(\boldsymbol{v}_c, w_{t+j}, \boldsymbol{U})\)是外围词是外围词\(w_{t+j}\)在中心词在中心词\(c=w_t\) 下产生的损失,损失函数可以是naive-softmax或者是neg-sample(负采样),这取决于具体实现。
计算:
损失函数对 \(U\) 的偏导数
损失函数对 \(\boldsymbol{v}_c\) 的偏导数
损失函数对 \(\boldsymbol{v}_w\) 的偏导数
$$
代码:实现word2vec(20分)
点击 此处 下载代码,python版本 >= 3.5,需要安装numpy,你利用conda来配置环境:
1 | |
写完代码后,运行:
1 | |
问题(a) (12分)
首先,实现 word2vec.py 里的 sigmoid函数,要支持向量输入。接着实现同一个文件里的 softmax 、负采样损失和导数。然后实现skip-gram的损失函数和导数。全部做完之后,运行python word2vec.py来检查是否正确。
答:
sigmoid
numpy具备广播特性,最终得到向量输出
1 | |
naiveSoftmaxLossAndGradient
这个模型其实就是一个三层的前馈神经网络,只需要注意维度即可,注释里已经标记出了维度。
需要注意的是,单词表示是在行,而不是列。
1 | |
negSamplingLossAndGradient
与native-softmax不同的是:
- 只选取K个非外围词作为负样本,加上1个正确的外围词,共K+1个输出
- 最后一层使用sigmoid输出,而不是softmax
注意,反向传播得到的是这K+1个词的梯度,所以需要挨个更新到 梯度矩阵 中去
1 | |
skipgram
遍历所有的外围词,求和损失函数
1 | |
问题(b) (4分)
完成sgd.py文件的SGD优化器,运行python sgd.py来检查是否正确。
答:
sgd
调用函数得到损失值和梯度,更新即可
1 | |
问题(c) (4分)
至此所有的代码都写完了,接下来是下载数据集,这里我们使用Stanform Sentiment Treebank(SST)数据集,它可以用在简单的语义分析任务中去。通过运行 sh get_datasets.sh 可以获得该数据集,下载完成后运行 python run.py 即可。
注意:训练的时间取决于代码是否高效(即便是高效的实现,也要跑接近一个小时)
经过40,000次迭代后,最终结果会保存到 word_vectors.png 里。
答:

- 在上图中可以观察到,male->famale 和 king -> queen 这两条向量是平行的
- (women, famale),(enjoyable,annoying) 这些含义接近的词距离很近
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!