第四讲-神经网络反向传播与计算图
1.简单神经网络的梯度矩阵与建议
1.1 权重矩阵的导数
让我们仔细看看计算\(\frac{\partial s}{\partial W}\)
再次使用链式法则:
\[ \frac{\partial s}{\partial W}=\frac{\partial s}{\partial h} \frac{\partial h}{\partial z} \frac{\partial z}{\partial W} \]
\[ s=u^{T} h, \ \ \ h=f(z),\ \ \ z=Wx+b \]
1.2 反向传播梯度求导
这个函数(从上次开始)
\[ \frac{\partial s}{\partial W}=\delta \frac{\partial z}{\partial W}=\delta \frac{\partial}{\partial W} W x+b \]
考虑单个权重\(W_{ij}\)的导数
\(W_{ij}\)只对\(z_i\)有贡献
\[ \begin{aligned} \frac{\partial z_{i}}{\partial W_{i j}} &=\frac{\partial}{\partial W_{i j}} W_{i .} x+b_{i} \\ &=\frac{\partial}{\partial W_{i j}} \sum_{k=1}^{d} W_{i k} x_{k}=x_{j} \end{aligned} \]
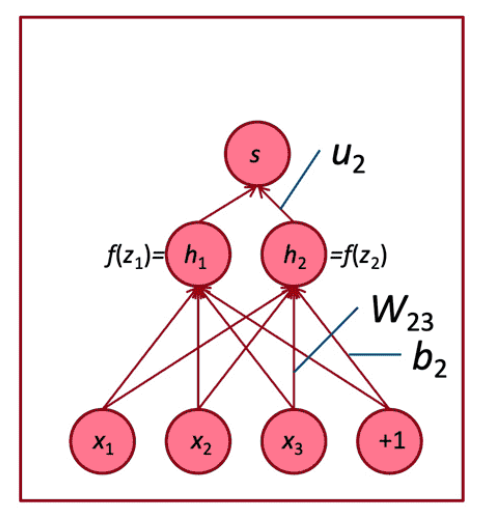
对于单个\(W_{ij}\)的导数
\[ \frac{\partial s}{\partial W_{i j}}=\delta_{i} x_{j} \]
我们想要整个\(W\)的梯度,但是每种情况都是一样的
解决方法:外积
\[ \begin{aligned} \frac{\partial s}{\partial W} &=\delta^{T} x^{T} \\ {[n \times m] } &=[n \times 1][1 \times m] \end{aligned} \]
1.3 为窗口模型推导梯度
到达并更新单词向量的梯度可以简单地分解为每个单词向量的梯度
令\(\nabla_{x} J=W^{T} \delta=\delta_{x_{\text {window }}}\)
\(X_{\text {window }}=\left[\begin{array}{lllll} X_{\text {museums }} & X_{\text {in }} & X_{\text {Paris }} & X_{\text {are }} & X_{\text {amazing }} \end{array}\right]\)
则得到\(\delta_{\text {window }}=\left[\begin{array}{c} \nabla_{x_{\text {museums }}} \\ \nabla_{x_{\text {in }}} \\ \nabla_{x_{\text {Pare }}} \\ \nabla_{x_{\text {are }}} \\ \nabla_{x_{\text {amazing }}} \end{array}\right] \in \mathbb{R}^{5 d}\)
我们将根据梯度逐个更新对应的词向量矩阵中的词向量,所以实际上是对词向量矩阵的更新是非常稀疏的
1.4 在窗口模型中更新单词梯度
- 当我们将梯度更新到词向量中时,这将更新单词向量,使它们(理论上)在确定命名实体时更有帮助。
- 例如,模型可以了解到,当看到\(x_{in}\)是中心词之前的单词时,指示中心词是一个 Location
1.5 重新训练词向量时的陷阱
背景:我们正在训练一个单词电影评论情绪的逻辑回归分类模型
在训练数据中,我们有“TV”和“telly”
在测试数据中我们有“television”
预训练的单词向量有三个相似之处:
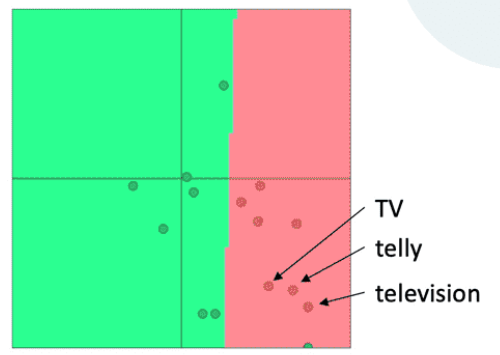
问题:当我们更新向量时会发生什么
回答:
- 那些在训练数据中出现的单词会四处移动
- “TV”和“telly”
- 没有包含在训练数据中的词汇保持原样
- “television”
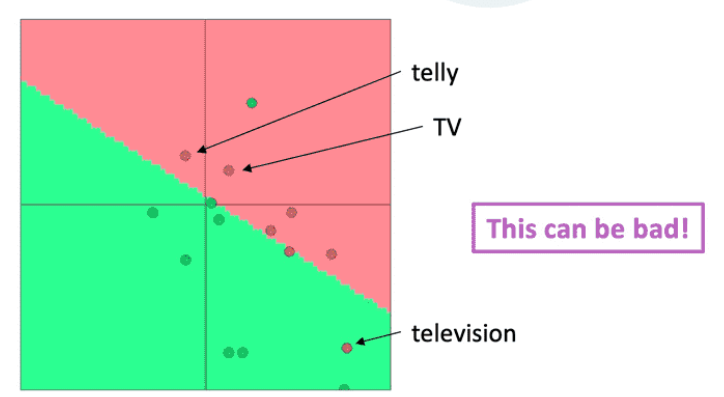
1.6 关于再训练的建议
问题:应该使用可用的“预训练”词向量吗?
回答:
- 几乎总是「应该用」
- 他们接受了大量的数据训练,所以他们会知道训练数据中没有的单词,也会知道更多关于训练数据中的单词
- 拥有上亿的数据语料吗?那可以随机初始化开始训练
问题:我应该更新(“fine tune”)我自己的单词向量吗?
回答:
- 如果你只有一个小的训练数据集,不要对预训练词向量做再训练
- 如果您有一个大型数据集,那么基于任务训练更新词向量( train = update = fine-tune )效果会更好
2.计算图与反向传播
2.1 反向传播
- 我们几乎已经向你们展示了反向传播
- 求导并使用(广义)链式法则
- 另一个技巧:在计算较低层的导数时,我们重用对较深层计算的导数,以减小计算量
2.2 计算图和反向传播
- 我们把神经网络方程表示成一个图
- 源节点:输入
- 内部节点:操作
- 边传递操作的结果
\[ \begin{array}{l} s=u^{T} h \\ h=f(z) \\ z=W x+b \\ x \quad(\text { input) } \end{array} \]
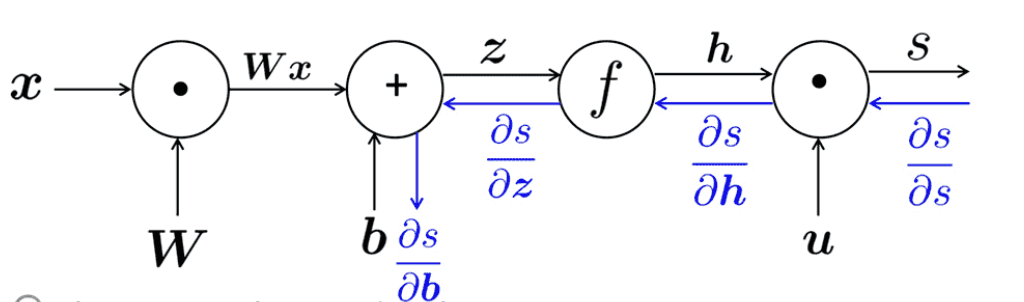
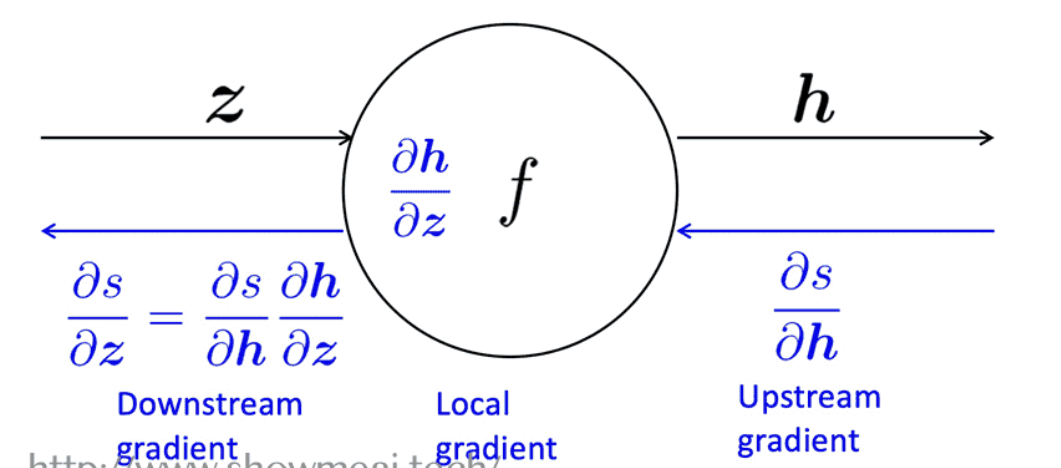
2.3 反向传播:单神经元视角
- 节点接收“上游梯度”
- 目标是传递正确的“下游梯度”
- 每个节点都有局部梯度 local gradient
- 它输出的梯度是与它的输入有关
- 下游梯度 = 上游梯度\(\times\)局部梯度
- 有多个输入的节点呢?
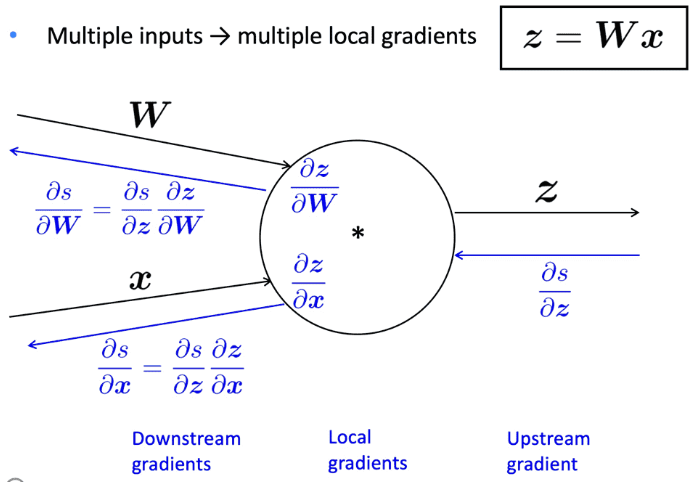
2.4 反向传播计算图示例

2.5 求和形态的梯度计算
上图中的\(\frac{\partial f}{\partial y}\)的梯度的计算 \[ \begin{array}{c} a=x+y \\ b=\max (y, z) \\ f=a b \\ \frac{\partial f}{\partial y}=\frac{\partial f}{\partial a} \frac{\partial a}{\partial y}+\frac{\partial f}{\partial b} \frac{\partial b}{\partial y} \end{array} \]
2.6 直挂理解神经元的梯度传递
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!