第六讲-循环神经网络与语言模型
1.语言模型
1.1 语言模型
1、语言建模的任务是预测下一个单词是什么
更正式的说法是:给定一个单词序列\(x^{(1)},x^{(2)},...,x^{(t)}\),计算下一个单词\(x^{(t+1)}\)的概率分布: \[ P(x^{(t+1)}| x^{(t)}, ..., x^{(1)}) \]
- 其中,\(x^{(t+1)}\)可以是词表中的任意单词\(V={w_1,...,w_v}\)
- 这样做的系统称为 Language Model 语言模型
2、还可以将语言模型看作评估一段文本是自然句子(通顺度)的概率
例如,如果我们有一段文本\(x^{(1)},x^{(2)},...,x^{(T)}\),则这段文本的概率(根据语言模型)为 \[ \begin{aligned} P\left(\boldsymbol{x}^{(1)}, \ldots, \boldsymbol{x}^{(T)}\right) &=P\left(\boldsymbol{x}^{(1)}\right) \times P\left(\boldsymbol{x}^{(2)} \mid \boldsymbol{x}^{(1)}\right) \times \cdots \times P\left(\boldsymbol{x}^{(T)} \mid \boldsymbol{x}^{(T-1)}, \ldots, \boldsymbol{x}^{(1)}\right) \\ &=\prod_{t=1}^{T} P\left(\boldsymbol{x}^{(t)} \mid \boldsymbol{x}^{(t-1)}, \ldots, \boldsymbol{x}^{(1)}\right) \end{aligned} \]
- 语言模型提供的是\(\prod_{t=1}^{T} P\left(\boldsymbol{x}^{(t)} \mid \boldsymbol{x}^{(t-1)}, \ldots, \boldsymbol{x}^{(1)}\right)\)
1.2 n-gram 语言模型
1 | |
问题:如何学习一个语言模型?
回答(深度学习之前的时期):学习一个 n-gram 语言模型
定义:n-gram是一个由\(n\)个连续单词组成的块
- unigrams:
the,students,opened,their - bigrams:
the students,students opened,opened their - trigrams:
the students opened,students opened their - 4-grams:
the students opened their
想法:收集关于不同 n-gram 出现频率的统计数据,并使用这些数据预测下一个单词
首先,我们做一个简化假设:\(x^{(t+1)}\)只依赖于前面的\(n-1\)个单词 \[ P\left(\boldsymbol{x}^{(t+1)} \mid \boldsymbol{x}^{(t)}, \ldots, \boldsymbol{x}^{(1)}\right)=P(\boldsymbol{x}^{(t+1)} \mid \overbrace{\left.\boldsymbol{x}^{(t)}, \ldots, \boldsymbol{x}^{(t-n+2)}\right)}^{n-1 \text { words }} \] 问题:如何得到n-gram和(n-1)-gram的概率?
回答:通过在一些大型文本语料库中计算它们(统计近似) \[ \approx \frac{\operatorname{count}\left(\boldsymbol{x}^{(t+1)}, \boldsymbol{x}^{(t)}, \ldots, \boldsymbol{x}^{(t-n+2)}\right)}{\operatorname{count}\left(\boldsymbol{x}^{(t)}, \ldots, \boldsymbol{x}^{(t-n+2)}\right)} \]
1.3 n-gram 语言模型:示例
假设我们正在学习一个 4-gram 的语言模型
as the proctor started the clock, the students opened their ____我们只需要考虑students opened their _____
- 例如,假设在语料库中:
students opened their出现了1000次students opened their books出现了400次
\[ P(books|students \ opened \ their) = 0.4 \]
students opened their exams出现了100次
\[ P(exams|students \ opened \ their) = 0.1 \]
- 我们应该忽视上下文中的proctor吗?
- 在本例中,上下文里出现了
proctor,所以exams在这里的上下文中应该是比books概率更大的。
- 在本例中,上下文里出现了
1.4 n-gram语言模型的稀疏性问题
问题1:如果students open their ww
从未出现在数据中,那么概率值为0
- (Partial)解决方案:为每个\(w\in V\)添加极小数\(\delta\),这叫做平滑。这使得词表中的每个单词都至少有很小的概率。
问题2:如果students open their
从未出现在数据中,那么我们将无法计算任何单词\(w\)的概率值
(Partial)解决方案:将条件改为
open their,也叫做后退处理。Note/注意: \(n\)的增加使稀疏性问题变得更糟。一般情况下\(n\)不能大于5。
1.5 n-gram语言模型的存储问题
问题:需要存储你在语料库中看到的所有 n-grams 的计数
增加\(n\)或增加语料库都会增加模型大小
1.6 n-gram语言模型的生成文本
可以使用语言模型来生成文本
使用trigram运行以上生成过程时,会得到上图左侧的文本
令人惊讶的是其具有语法但是是不连贯的。如果我们想要很好地模拟语言,我们需要同时考虑三个以上的单词。但增加\(n\)使模型的稀疏性问题恶化,模型尺寸增大
1.7 如何搭建一个神经语言模型?
回忆一下语言模型任务
- 输入:单词序列\(x^{(1)}, x^{(2)}, ...,x^{(t)}\)
- 输出:下一次单词的概率\(P\left(\boldsymbol{x}^{(t+1)} \mid \boldsymbol{x}^{(t)}, \ldots, \boldsymbol{x}^{(1)}\right)\)
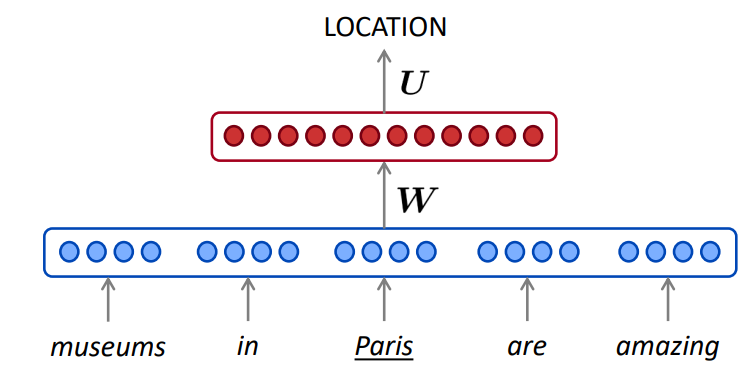
1.8 固定窗口的神经语言模型
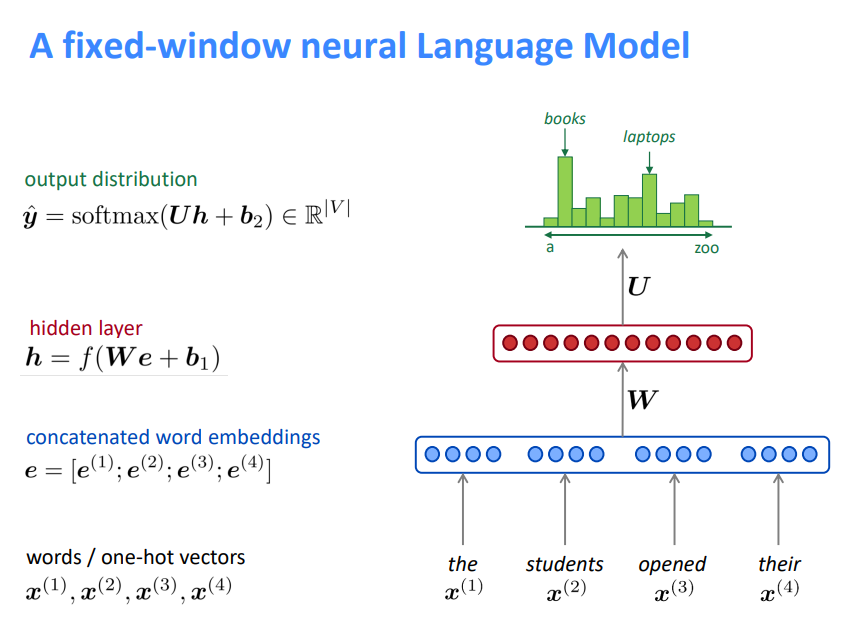
超越 n-gram 语言模型的改进
- 没有稀疏性问题
- 不需要观察到所有的n-grams
NNLM存在的问题
- 固定窗口太小
- 扩大窗口就需要扩大权重矩阵\(W\)
- 窗口再大也不够用
- \(x^{(1)}\)和\(x^{(2)}\)乘以完全不同的权重。输入的处理不对称
我们需要一个神经结构,可以处理任何长度的输入
2.循环神经网络(RNN)
2.1 循环神经网络(RNN)
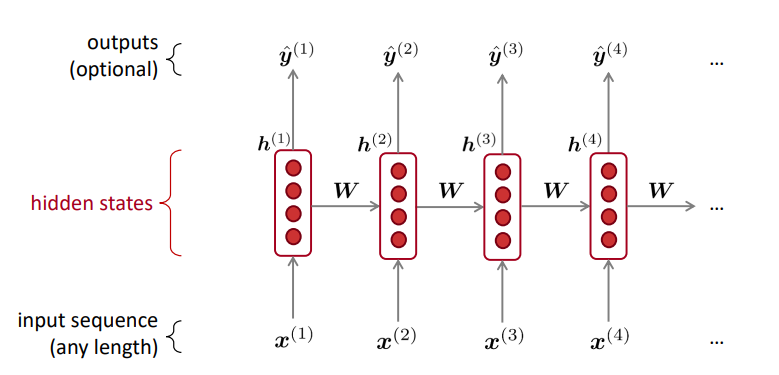
- RNN的优点
- 可以处理任意长度的输入
- 步骤\(t\)的计算(理论上)可以使用许多步骤前的信息
- 模型大小不会随着输入的增加而增加
- 在每个时间步上应用相同的权重,因此在处理输入时具有对称性
- RNN的缺点
- 循环串行计算速度慢
- 在实践中,很难从许多步骤前返回信息
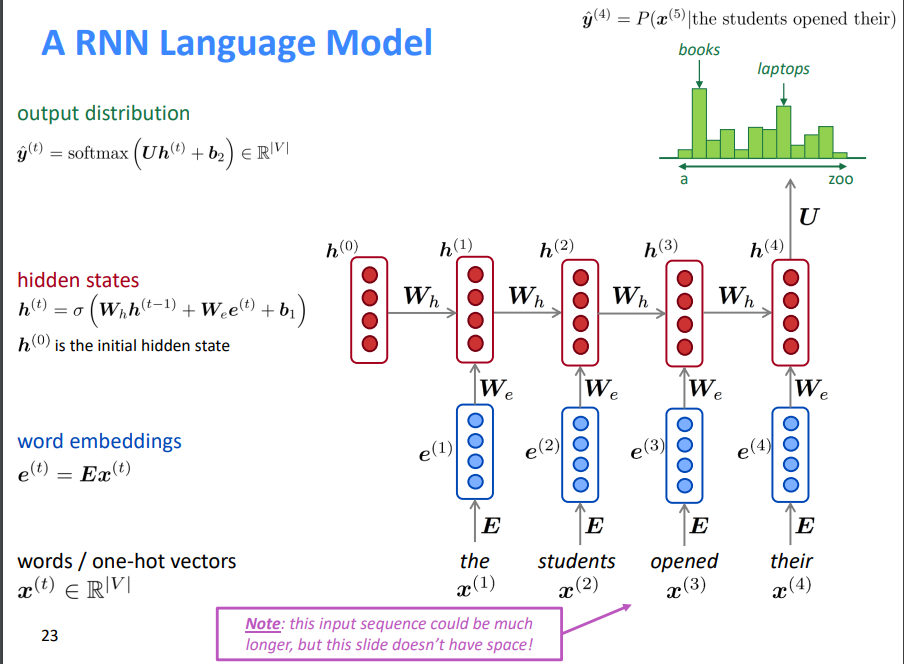
2.2 训练一个RNN语言模型
获取一个较大的文本语料库,该语料库是一个单词序列
输入RNN-LM;计算每个步骤的输出分布
- 即预测到目前为止给定的每个单词的概率分布
步骤\(t\)上的损失函数为预测概率分布\(\hat{y}^{(t)}\)与真实下一个单词\(y^{(t)}\)(\(x^{(t+1)}\)的独热向量)之间的交叉熵
\[
J^{(t)}(\theta)=C E\left(\boldsymbol{y}^{(t)},
\hat{\boldsymbol{y}}^{(t)}\right)=-\sum_{w \in V}
\boldsymbol{y}_{w}^{(t)} \log \hat{\boldsymbol{y}}_{w}^{(t)}=-\log
\hat{\boldsymbol{y}}_{\boldsymbol{x}_{t+1}}^{(t)}
\] 将其平均,得到整个训练集的总体损失 \[
J(\theta)=\frac{1}{T} \sum_{t=1}^{T} J^{(t)}(\theta)=\frac{1}{T}
\sum_{t=1}^{T}-\log \hat{\boldsymbol{y}}_{\boldsymbol{x}_{t+1}}^{(t)}
\] 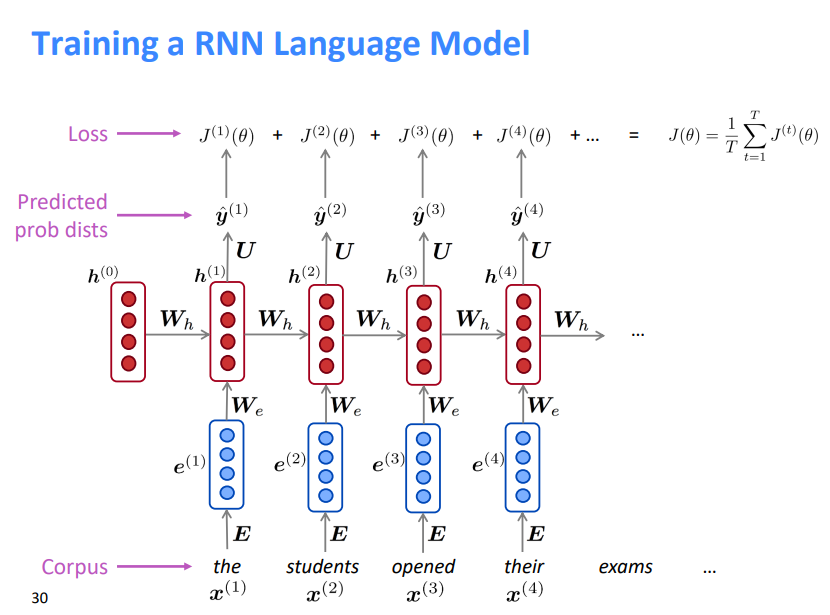
然而:计算整个语料库\(x^{(1)},...,x^{(T)}\)的损失和梯度太昂贵了,所以在实践中通常把\(x^{(1)},...,x^{(T)}\)看成一个句子或是文档
回忆:随机梯度下降允许我们计算小块数据的损失和梯度,并进行更新
计算一个句子的损失\(J(\theta)\)(实际上是一批句子),计算梯度和更新权重。重复上述操作。
2.3 RNN的反向传播
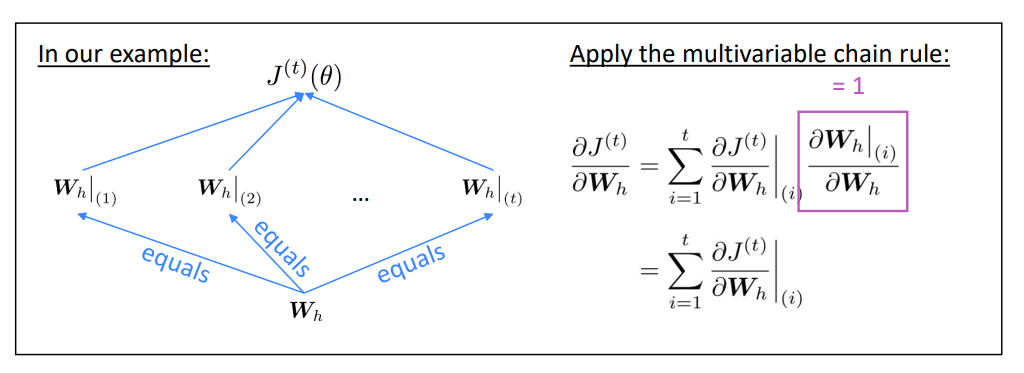
问题:关于重复的权重矩阵\(W_h\)的偏导数\(J^{(t)}(\theta)\)
回答:重复权重的梯度是每次其出现时的梯度的总和 \[
\frac{\partial J^{(t)}}{\partial
\boldsymbol{W}_{\boldsymbol{h}}}=\left.\sum_{i=1}^{t} \frac{\partial
J^{(t)}}{\partial \boldsymbol{W}_{\boldsymbol{h}}}\right|_{(i)}
\] 
问题:如何计算?
回答:反向传播的时间步长\(i=t,...,0\)。累加梯度。这个算法叫做 “backpropagation through time”
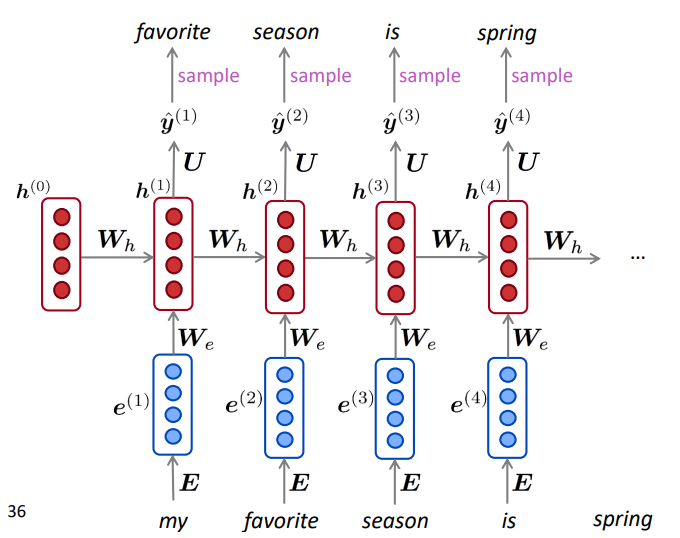
2.4 RNN语言模型的生成文本
就像n-gram语言模型一样,你可以使用RNN语言模型通过重复采样来生成文本。采样输出是下一步的输入。
3.评估语言模型
3.1 评估语言模型
标准语言模型评估指标是 perplexity 困惑度这等于交叉熵损失\(J(\theta)\)的指数 \[ =\prod_{t=1}^{T}\left(\frac{1}{\hat{y}_{x_{t+1}}^{(t)}}\right)^{1 / T}=\exp \left(\frac{1}{T} \sum_{t=1}^{T}-\log \hat{\boldsymbol{y}}_{\boldsymbol{x}_{t+1}}^{(t)}\right)=\exp (J(\theta)) \] 困惑度越低效果越好
3.2 RNN极大地改善了困惑度
语言模型是一项基准测试任务,它帮助我们衡量我们在理解语言方面的进展
- 生成下一个单词,需要语法,句法,逻辑,推理,现实世界的知识等
语言建模是许多NLP任务的子组件,尤其是那些涉及生成文本或估计文本概率的任务
- 预测性打字、语音识别、手写识别、拼写/语法纠正、作者识别、机器翻译、摘要、对话等等
3.3 要点回顾
语言模型(LM: Language Model):预测下一个单词的系统
循环神经网络:一系列神经网络
- 采用任意长度的顺序输入
- 在每一步上应用相同的权重
- 可以选择在每一步上生成输出
循环神经网络\(\ne\)语言模型,我们已经证明,RNNs是构建LM的一个很好的方法,但RNNs的用处要大得多!
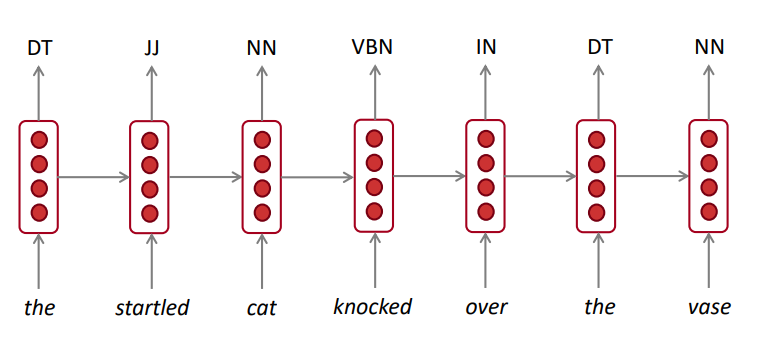
3.4 RNN可用于打标签
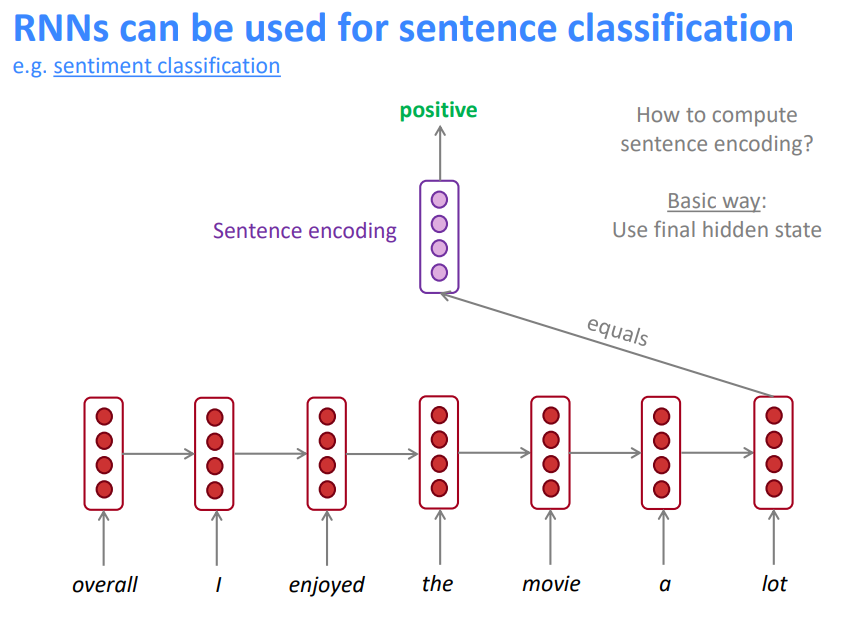
3.5 RNN可用于句子分类
如何计算句子编码
基础方式:使用最终隐层状态
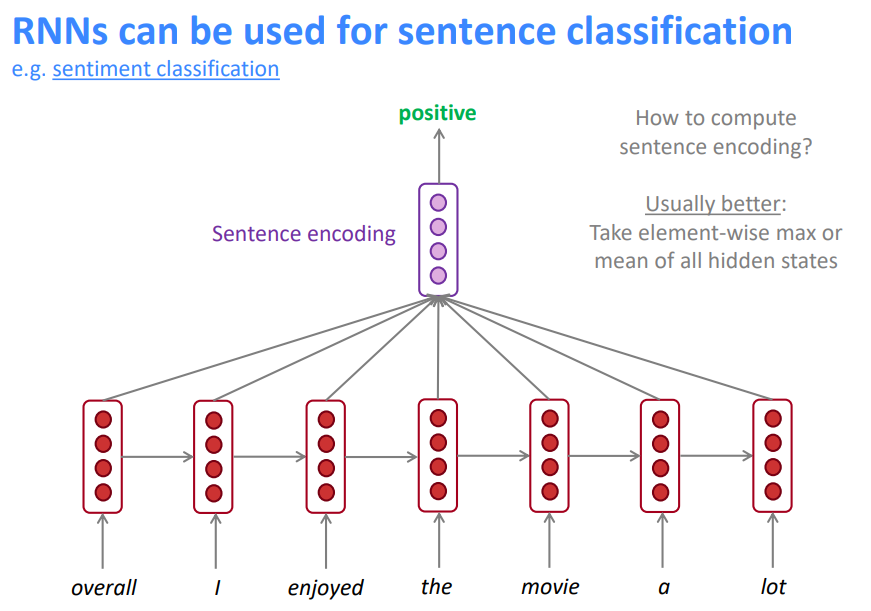
通常更好的方式:使用所有隐层状态的逐元素最值或均值,Encoder的结构在NLP中非常常见
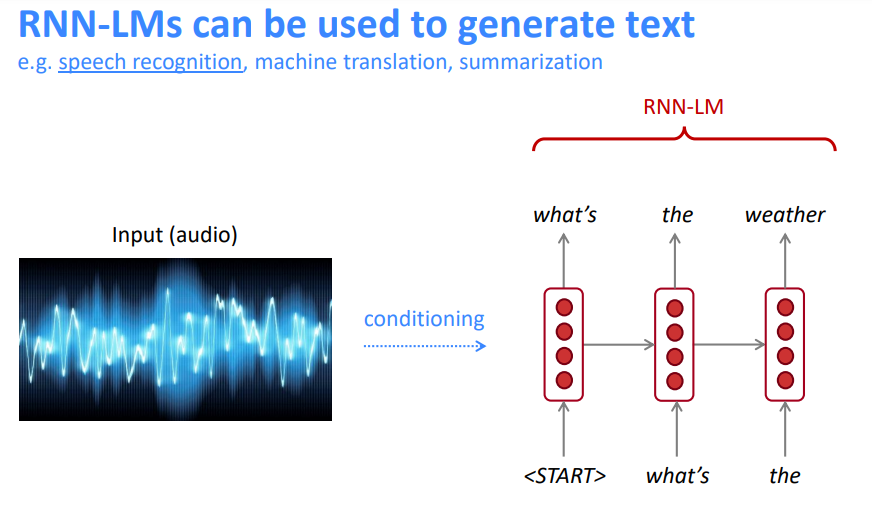
3.6 RNN语言模型可用于生成文本
这是一个条件语言模型的示例。我们使用语言模型组件,并且最关键的是,我们根据条件来调整它
参考:
http://www.showmeai.tech/article-detail/240
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!