论文:Masked Autoencoders Are Scalable Vision Learners
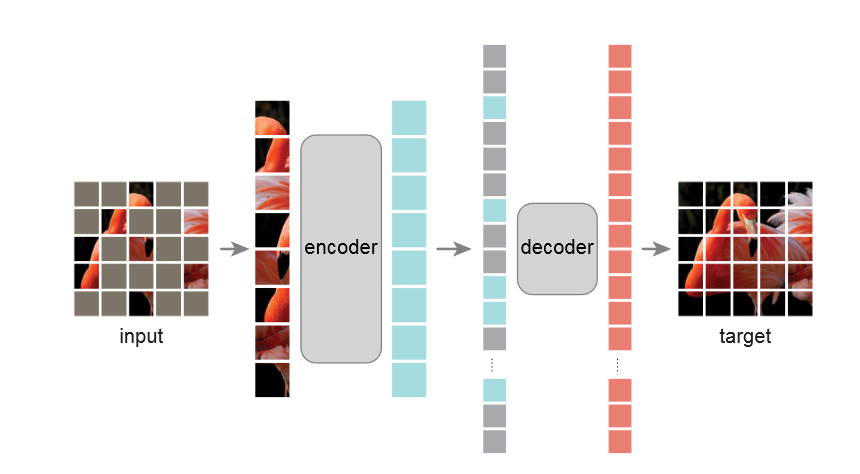
模型图
Approach
Masking
MAE使用了ViT的方法,将图片分割成一个个小块,然后在这些小块中随机、均匀地选取一部分保留,剩下的全部遮蔽。作者强调了要遮蔽大量的像素块(约75%),从而减少像素块之间的冗余信息,使整个任务更具有挑战性,迫使模型去学习图像的全局特征而非局部特征,从而获得更优的图像重构能力。
MAE encoder
encode用的就是一个完整的ViT,其输入仅为没有被mask的patch,节省了计算开支,可以通过较小的计算和内存来训练出较大的encoder。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class MAE_Encoder (torch.nn.Module):def __init__ (self, image_size=32 , patch_size=2 , emb_dim=192 , num_layer=12 , num_head=3 , mask_ratio=0.75 , ) -> None :super ().__init__()1 , 1 , emb_dim)) 2 , 1 , emb_dim))3 , emb_dim, patch_size, patch_size)for _ in range (num_layer)])def init_weight (self ):.02 ).02 )def forward (self, img ):'b c h w -> (h w) b c' )1 , patches.shape[1 ], -1 ), patches], dim=0 )'t b c -> b t c' )'b t c -> t b c' )return features, backward_indexes
MAE decoder
decoder 的输入是整个 tokens 的集合,包含
编码好的可见的 patches
mask tokens
每一个 mask token
都是共享的,学习的向量,表示这里存在一个有待预测的缺失 patch。我们将位置
embedding 添加到这个完整集合中的所有 tokens 中 ;如果不这样做, mask
tokens 就没有他们在图像中位置的信息。
解码器还有另一系列Transformer块
decoder 只用在预训练过程中使用。因此,decoder 结构可以以独立于
encoder 设计的方式灵活设计。我们用很小的 decoder进行实验,比 encoder
更小,更窄。例如,我们默认的 decoder 对每个 token 的计算量小于 encoder
的 10%。
在这种非对称设计中,完整的 token 集合只由轻量级 decoder 处理(encoder
只处理可见的 tokens),这大大减少了预训练时间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class MAE_Decoder (torch.nn.Module):def __init__ (self, image_size=32 , patch_size=2 , emb_dim=192 , num_layer=4 , num_head=3 , ) -> None :super ().__init__()1 , 1 , emb_dim))2 + 1 , 1 , emb_dim))for _ in range (num_layer)])3 * patch_size ** 2 )'(h w) b (c p1 p2) -> b c (h p1) (w p2)' , p1=patch_size, p2=patch_size, h=image_size//patch_size)def init_weight (self ):.02 ).02 )def forward (self, features, backward_indexes ):0 ]1 , backward_indexes.shape[1 ]).to(backward_indexes), backward_indexes + 1 ], dim=0 )0 ] - features.shape[0 ], features.shape[1 ], -1 )], dim=0 )'t b c -> b t c' )'b t c -> t b c' ) 1 :] 1 1 :] - 1 )return img, mask
Reconstruction target
我们的 MAE 通过预测为 masked patch
预测每个像素值来重建输入,每个元素在 decoder 中的输出都是表达一个 patch
中像素值的向量。decoder 的最后一层是一个 linear
projection,其输出的通道数等于一个 patch 中的像素值的个数。decoder
的输出被 reshape 来组成重建的图。
我们的 loss function 在像素空间上计算了重建图像和原图像的
MSE(平方差)。我们值计算了 masked patches 的 loss,就像 BEiT 那样。
我们还研究了一个变种,他的重建目标是每个 masked patch
的归一化像素值。具体来说,我们计算一个patch中所有像素的均值和标准差,然后用它们来归一化这个patch。在实验中,使用归一化像素作为重建目标提高了表示质量。
Simple implementation
我们的MAE预训练可以高效地实施,而且重要的是,不需要任何专门的稀疏操作。
首先,我们为每个input patch生成一个 token(先使用 Linear
Projection,然后加上位置 embedding)。
接下来,我们将随机洗牌 tokens list,并根据屏蔽比率删除 list
的最后一部分。这个过程为encoder产生了一个tokens
的小的集合,和无替换地采样 patches 是一样的。
在 encoding 之后,我们向 encoded patch list 中添加一个 mask tokens
list,然后反洗牌整个list(和前面的洗牌操作是相反的)以将所有的tokens和tragets对齐
decoder 在整个 list 上应用(带有添加的位置 embedding)。
如前所述,不需要进行稀疏操作。这个简单的实现引入的开销可以忽略不计,因为洗牌和反洗牌操作非常快。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class MAE_ViT (torch.nn.Module):def __init__ (self, image_size=32 , patch_size=2 , emb_dim=192 , encoder_layer=12 , encoder_head=3 , decoder_layer=4 , decoder_head=3 , mask_ratio=0.75 , ) -> None :super ().__init__()def forward (self, img ):return predicted_img, mask