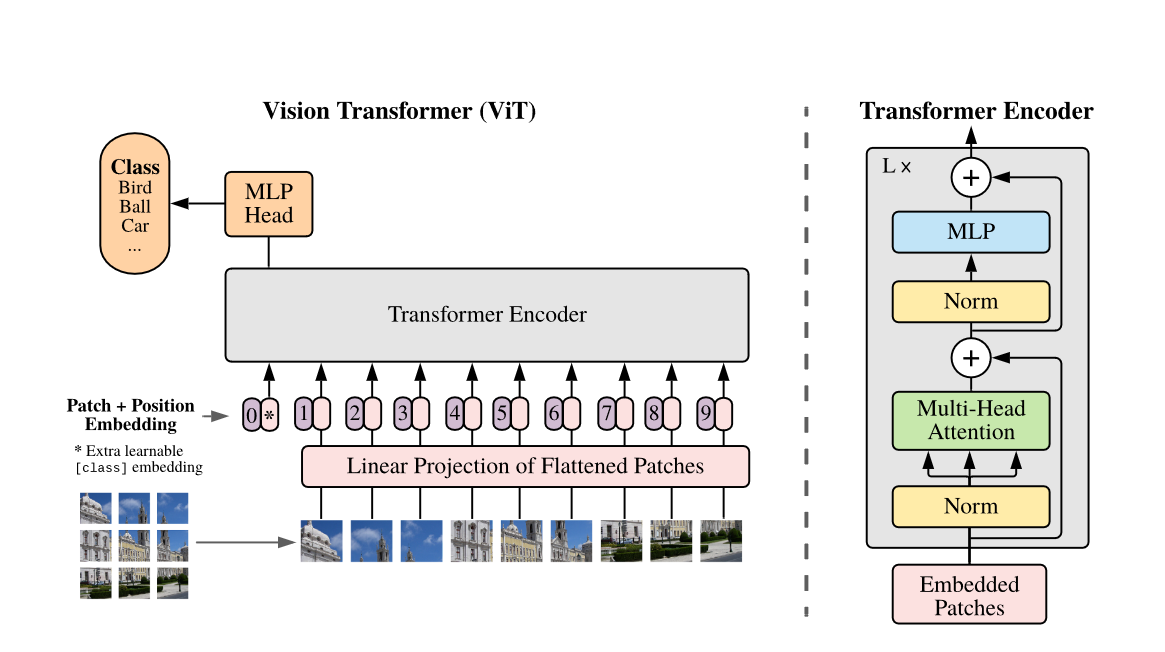
classViT(nn.Module): def__init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, channels=3, dropout=0., emb_dropout=0.): super().__init__() assert image_size % patch_size == 0, 'Image dimensions must be divisible by the patch size.' num_patches = (image_size // patch_size) ** 2 patch_dim = channels * patch_size ** 2 assert num_patches > MIN_NUM_PATCHES, f'your number of patches ({num_patches}) is way too small for attention to be effective (at least 16). Try decreasing your patch size'
defforward(self, img, mask=None): p = self.patch_size
x = self.patch_to_embedding(x) b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '() n d -> b n d', b=b) x = torch.cat((cls_tokens, x), dim=1) x += self.pos_embedding[:, :(n + 1)] x = self.dropout(x)
x = self.transformer(x, mask)
x = self.to_cls_token(x[:, 0]) return self.mlp_head(x)