import torch import torch.nn as nn from torchsummary import summary from torch.nn import Conv2d from einops.layers.torch import Rearrange, Reduce from tensorboardX import SummaryWriter
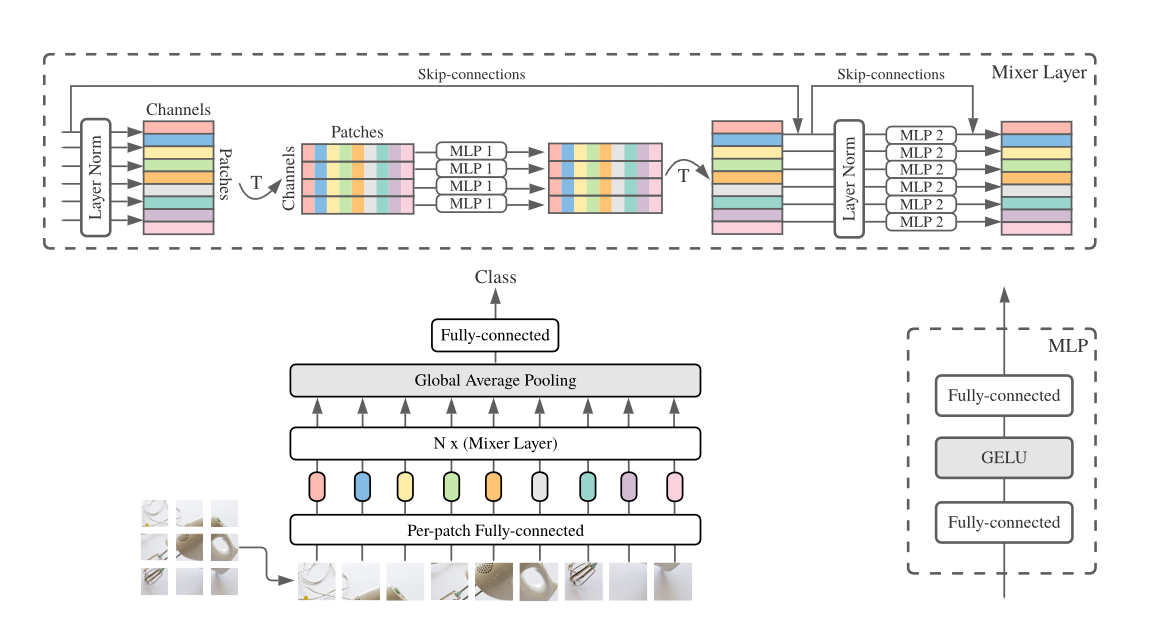
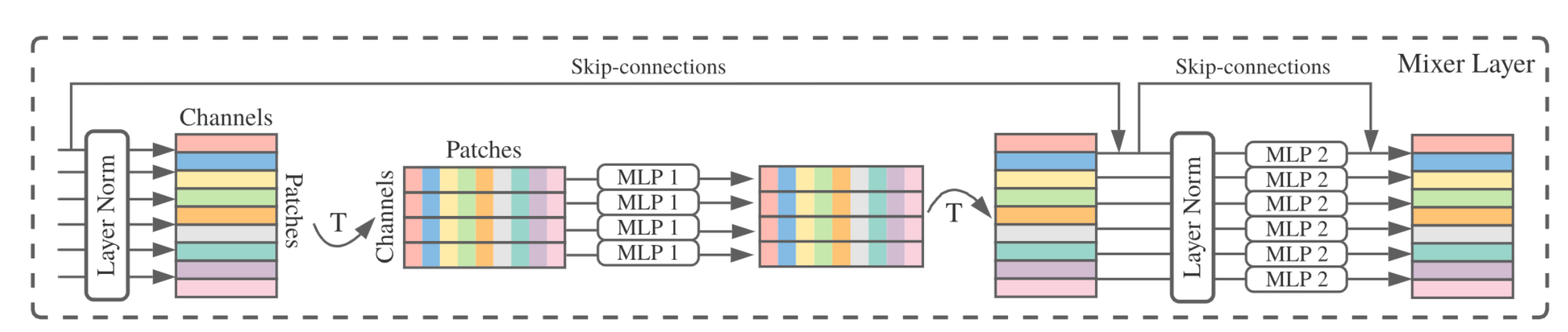
classMixerBlock(nn.Module): def__init__(self,dim,num_patch,token_dim,channel_dim,dropout=0.): super().__init__() self.token_mixer=nn.Sequential( nn.LayerNorm(dim), Rearrange('b n d -> b d n'), FeedForward(num_patch,token_dim,dropout), Rearrange('b d n -> b n d')
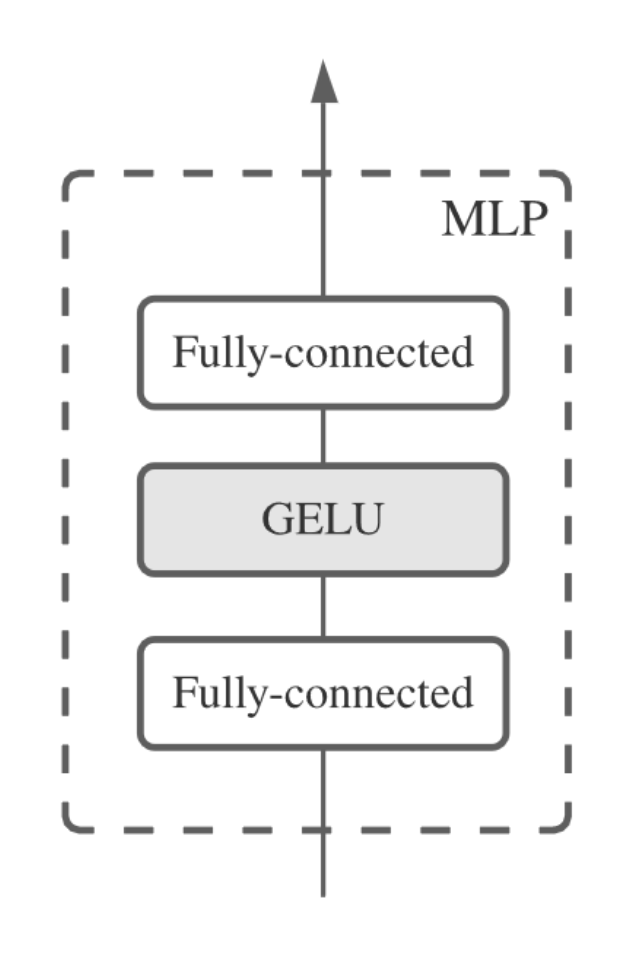
) self.channel_mixer=nn.Sequential( nn.LayerNorm(dim), FeedForward(dim,channel_dim,dropout) ) defforward(self,x): x = x+self.token_mixer(x) x = x+self.channel_mixer(x) return x
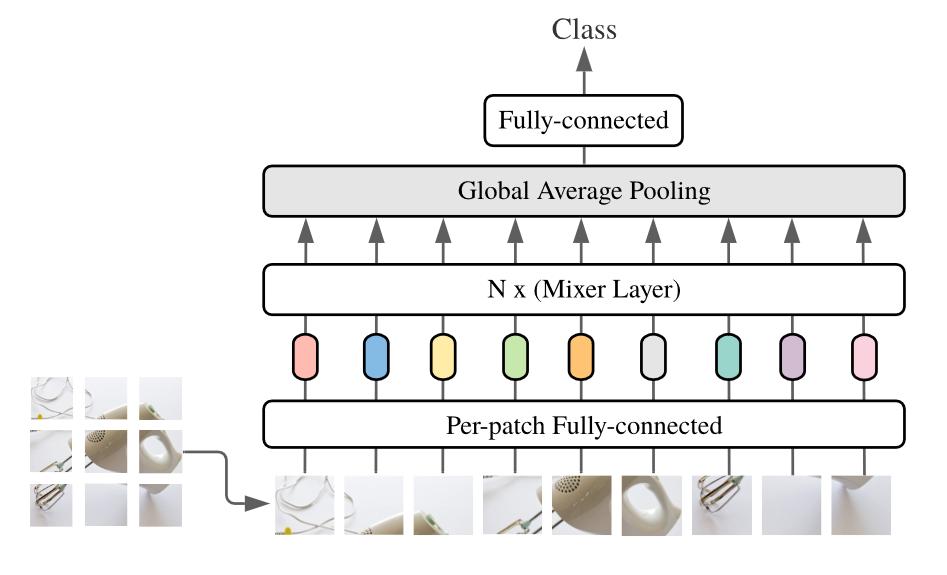
# self.mlp_head=nn.Sequential( nn.Linear(dim,num_classes) ) defforward(self,x): x = self.to_embedding(x) for mixer_block in self.mixer_blocks: x = mixer_block(x) x = self.layer_normal(x) x = x.mean(dim=1)
x = self.mlp_head(x) return x
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
if __name__ == '__main__': device = torch.device("cuda:0"if torch.cuda.is_available() else"cpu") model = MLPMixer(in_channels=3, dim=512, num_classes=1000, patch_size=16, image_size=224, depth=1, token_dim=256, channel_dim=2048).to(device) summary(model,(3,224,224))