MAXIM
- 论文:MAXIM: Multi-Axis MLP for Image Processing

摘要
文章提出了一种基于多轴MLP的底层图像处理任务的架构:MAXIM。MAXIM使用U-net的结构。具体来说,MAXIM包含两个基于MLP的块:一个多轴门控MLP(multi-axis gated MLP),可以在局部/全局视觉信息上进行充分的空间混合;一个交叉门控块(cross-gating block),作为交叉注意力的替代方案。MAXIM既能具有局部/全局感受野,也能满足低层次视觉任务需要的全卷积特性。模型在5个图像处理任务(去噪、去模糊、去雾、去雨、图像增强)的10多个数据集上均达到SOTA。
Contribution
- 提出一种新的应用于图像处理任务的架构:MAXIM,在去噪、去模糊、去雨、去雾、图像增强等多个领域的10多个数据集上均取得SOTA结果;
- 提出一种多轴门控MLP模块(Multi-axis gated MLP block),具有全局感受野和全卷积特性,同时只需要线性复杂度;
- 提出一种交叉门控模块(Cross-Gating block),用来调制Encoder到Decoder之间的skip connection,同样具有全局感受野和全卷积特性;
模型结构
整体结构
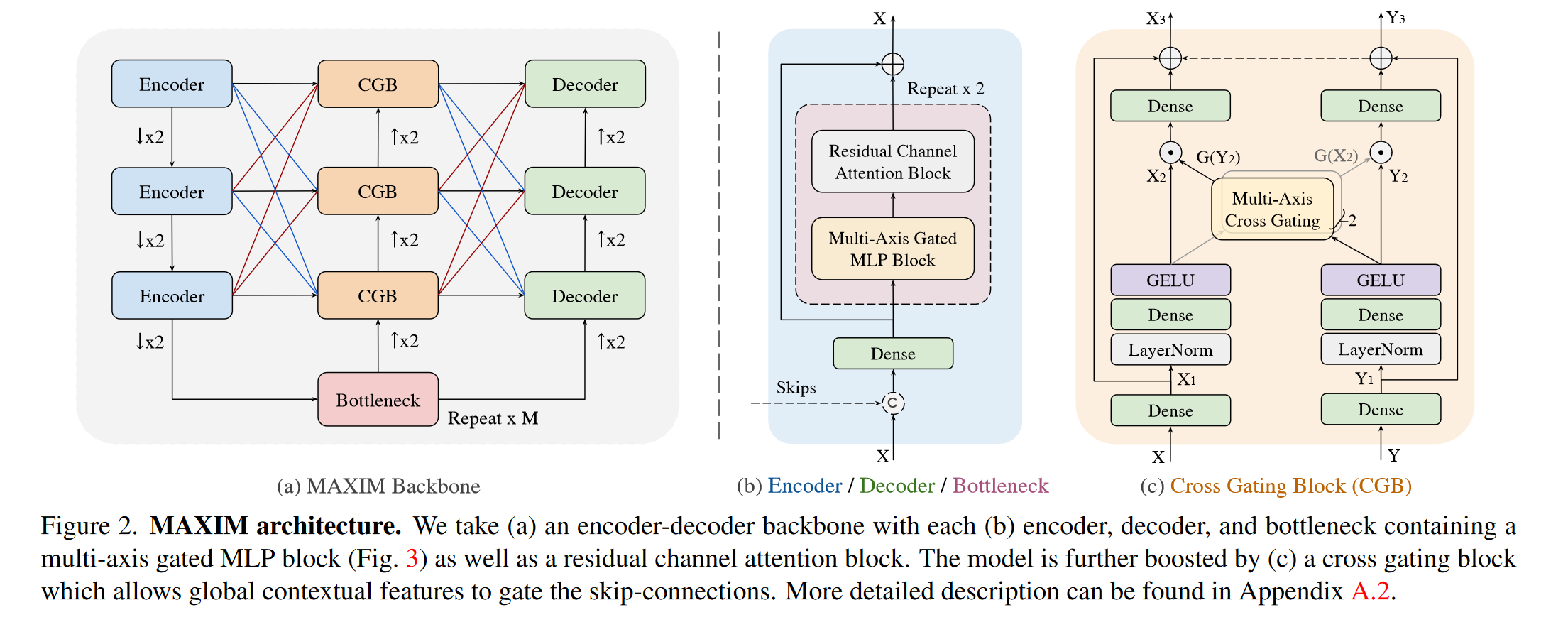
多轴门控MLP(Multi-Axis Gated MLP Block)
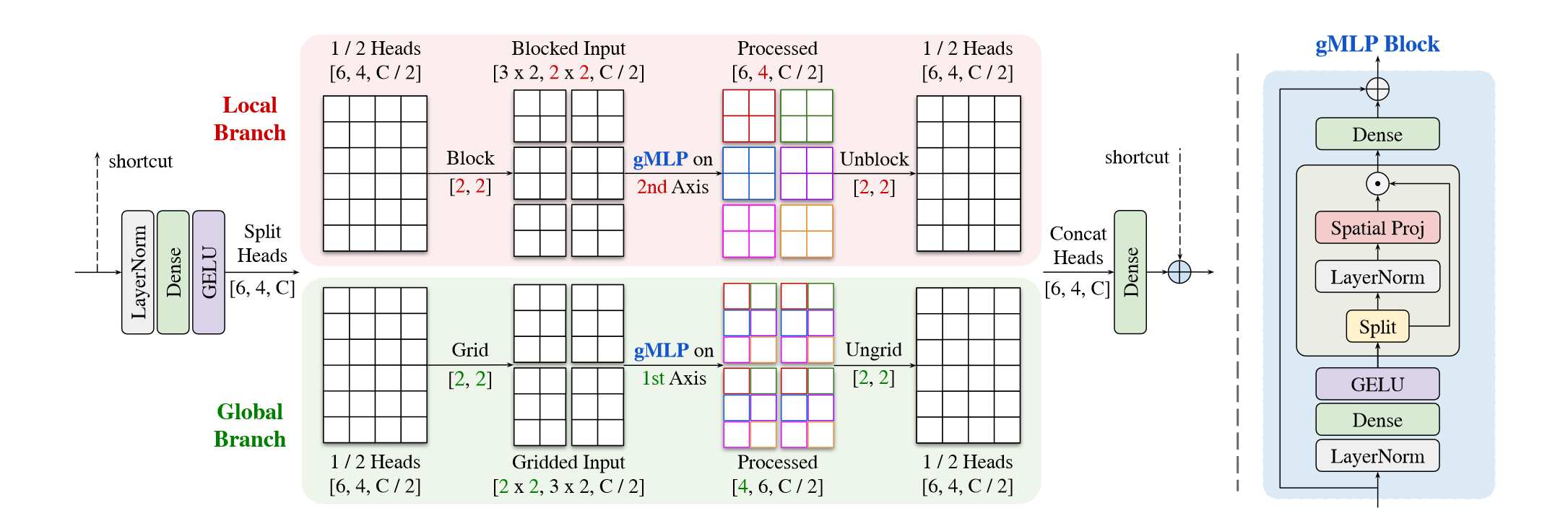
如图,输入特征图首先通过LayerNorm-Dense-GELU,随后沿通道维度分为两个部分,分别进行局部/全局的空间交互。
上半部分的Local Branch将图像划分为固定窗口大小 \(b \times b\) 的blcok,特征图尺寸由 \([H,W,C]\) 变为 \(\left[\frac{H}{b} \times \frac{W}{b}, b \times b, C\right]\),随后在第二个维度进行gMLP计算,其余维度共享参数,随后通过一个unblock恢复为 \([H,W,C]\) 的尺寸;下半部分的Global Branch与上半部分类似,区别在于采用固定的窗口个数,以及Global Branch是在第一个维度进行gMLP计算。
最后将Local Branch和Global Branch的结果进行Concat后通过Dense变换减少通道数,与输入进行长距离连接结合。
这样,上半部分采用关注每个固定大小block的局部感受野,下半部分采用关注grid每个部分的全局感受野;而且因为MLP是在一个固定的、和图像尺寸无关维度进行的,这样的变换可以实现全卷积,且是线性的时间复杂度: \[ \Omega(\mathrm{MAB})=\underbrace{d^{2} H W C}_{\text {Global gMLP }}+\underbrace{b^{2} H W C}_{\text {Local gMLP }}+\underbrace{10 H W C^{2}}_{\text {Dense layers }}\ \ \ \ \ \ \ (1) \]
交叉门控模块(Cross Gated MLP Block)
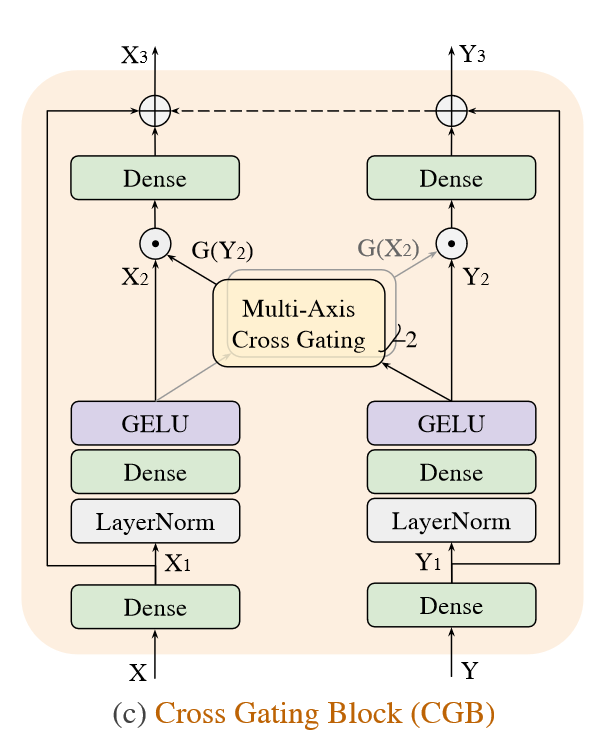
交叉门控模块用于U-net的skip connection中选择性地控制特征传播,通过一种交叉注意力机制实现
X、Y为输入的两个特征图,首先通过一个Dense变换分别得到 \(X_1\) 和 \(Y_1\) ;
随后通过LN-Dense-GELU得到 \(X_2\) 、 \(Y_2\) :
\[ \mathbf{X}_{2}=\sigma\left(\mathbf{W}_{1} \mathrm{LN}\left(\mathbf{X}_{1}\right)\right), \quad \mathbf{Y}_{2}=\sigma\left(\mathbf{W}_{2} \mathrm{LN}\left(\mathbf{Y}_{1}\right)\right)\ \ \ \ \ \ \ (2) \] 再通过交叉门控的方式得到 \(\hat{X}\) 和 \(\hat{Y}\)
\[ \hat{\mathbf{X}}=\mathbf{X}_{2} \odot \mathrm{G}\left(\mathbf{Y}_{2}\right), \quad \hat{\mathbf{Y}}=\mathbf{Y}_{2} \odot \mathrm{G}\left(\mathbf{X}_{2}\right)\ \ \ \ \ \ \ (3) \] 其中 \(\odot\) 代表element-wise multiplication,这里的G采用与(2)中多轴门控MLP相同的方法实现。 \[ \mathrm{G}(\mathbf{x})=\mathbf{W}_{5}\left(\left[\mathbf{W}_{3} \operatorname{Block}_{b}\left(\mathbf{z}_{1}\right), \mathbf{W}_{4} \operatorname{Grid}_{d}\left(\mathbf{z}_{\mathbf{2}}\right)\right]\right)\ \ \ \ \ \ \ (4) \] 其中 \([\cdot, \cdot]\) 代表concatenate,这里的 \((z_1, z_2)\) 是 \(z\) 从channel维度进行分割成的两个单独head \[ \left[\mathbf{z}_{1}, \mathbf{z}_{2}\right]=\mathbf{z}=\sigma\left(\mathbf{W}_{6} \mathbf{L N}(\mathbf{x})\right)\ \ \ \ \ \ \ (5) \] 最后通过一个残差连接得到输出 \(X_3\) 、 \(Y_3\) : \[ \mathbf{X}_{3}=\mathbf{X}_{1}+\mathbf{W}_{7} \hat{\mathbf{X}}, \quad \mathbf{Y}_{3}=\mathbf{Y}_{1}+\mathbf{W}_{8} \hat{\mathbf{Y}}\ \ \ \ \ \ \ (6) \] 这个交叉门控模块可以起到全局/局部感受野传递特征信息的作用,并且同样具有线性时间复杂度。
多阶段多尺度架构
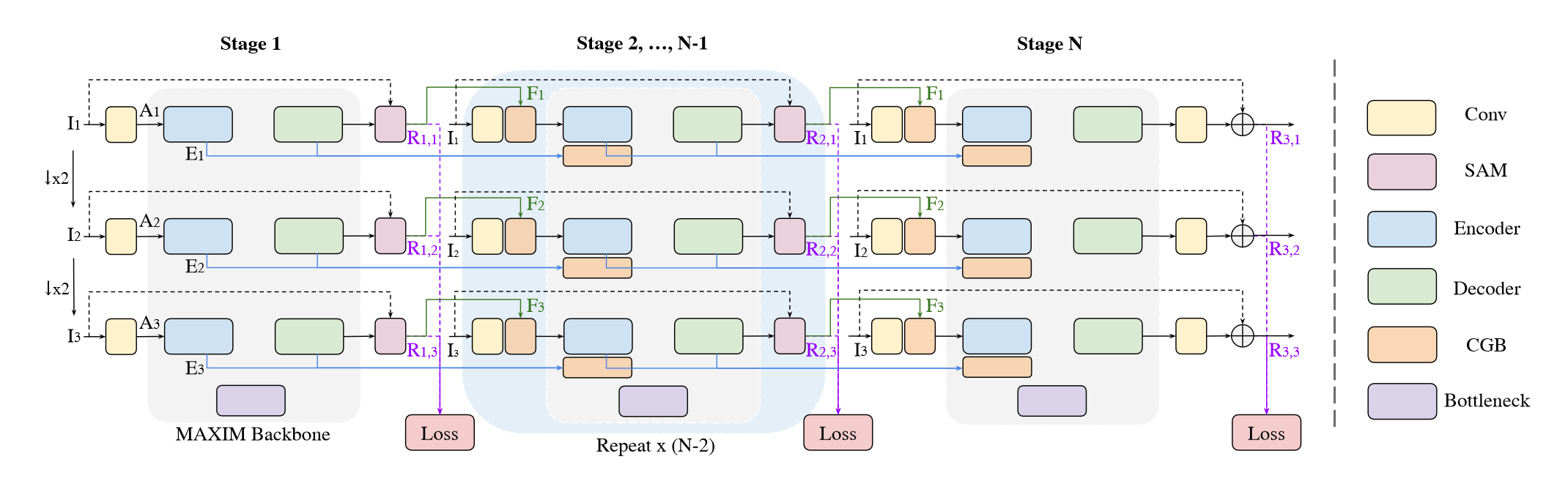
实验发现,使用多阶段小模型要比单阶段大模型的效果要好很多,所以文章采用了一种多阶段多尺度的结构来实现模型,如图所示,横向为多阶段,纵向为多尺度,最终输出结果为最后阶段的最大尺度输出
模型的损失函数为多个阶段、多个尺度的输出计算Charbonnier损失和频域变换的L1损失的加权: \[ \mathcal{L}=\sum_{s=1}^{S} \sum_{n=1}^{N}\left[\mathcal{L}_{c h a r}\left(\mathbf{R}_{s, n}, \mathbf{T}_{n}\right)+\lambda \mathcal{L}_{f r e q}\left(\mathbf{R}_{s, n}, \mathbf{T}_{n}\right)\right]\ \ \ \ \ \ \ (7) \] 其中 \(T_n\) 表示(双线性缩放)多尺度目标图像,\(\mathcal{L}_{c h a r}\) 是Charbonnier loss: \[ \mathcal{L}_{c h a r}(\mathbf{R}, \mathbf{T})=\sqrt{\|\mathbf{R}-\mathbf{T}\|^{2}+\epsilon^{2}}\ \ \ \ \ \ \ (8) \] 其中 \(\epsilon\) 我们设置为 \(10^{-3}\) ,\(\mathcal{L}_{f r e q}\) 是执行高频细节的频率重构损失: \[ \mathcal{L}_{\text {freq }}(\mathbf{R}, \mathbf{T})=\|\mathcal{F}(\mathbf{R})-\mathcal{F}(\mathbf{T})\|_{1}\ \ \ \ \ \ \ (9) \] 其中 \(\mathcal{F}\) 代表2D快速傅里叶变换。我们在所有实验中都使用 \(\lambda = 0.1\) 作为权重因子。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!