SimAM
论文:SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks

method
现有的注意力模块通常被继承到每个块中,以改进来自先前层的输出。这种细化步骤通常沿着通道维度或空间维度操作,这些方法生成一维或二维权重,并平等对待每个通道或空间位置中的神经元:
通道注意力:1D注意力,它对不同通道区别对待,对所有位置同等对待;
空间注意力:2D注意力,它对不同位置区别对待,对所有通道同等对待。 这可能会限制他们学习更多辨别线索的能力。因此三维权重优于传统的一维和二维权重注意力
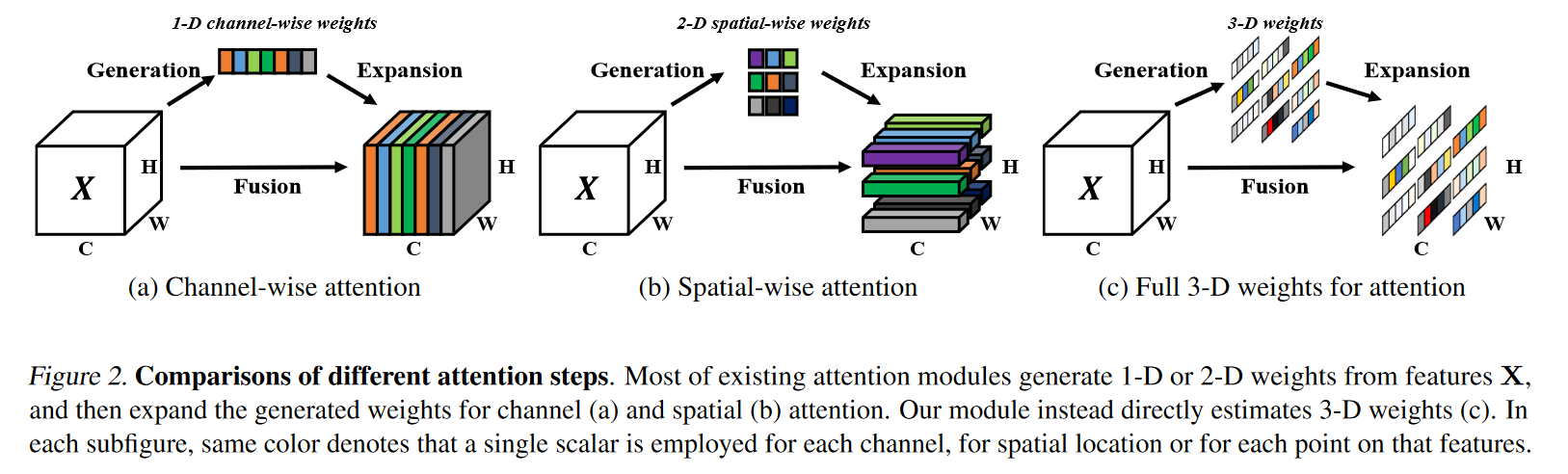
已有研究BAM、CBAM分别将空间注意力与通道注意力进行并行或串行组合。然而,人脑的两种注意力往往是协同工作,因此,我们提出了统一权值的注意力模块。为更好的实现注意力,我们需要评估每个神经元的重要性。在神经科学中,信息丰富的神经元通常表现出与周围神经元不同的放电模式。而且,激活神经元通常会抑制周围神经元,即空域抑制。换句话说,具有空域抑制效应的神经元应当赋予更高的重要性。最简单的寻找重要神经元的方法:度量神经元之间的线性可分性。基于这些神经科学发现,我们为每个神经元定义如下能量函数: \[ e_{t}\left(w_{t}, b_{t}, \mathbf{y}, x_{i}\right)=\left(y_{t}-\hat{t}\right)^{2}+\frac{1}{M-1} \sum_{i=1}^{M-1}\left(y_{o}-\hat{x}_{i}\right)^{2}\ \ \ \ \ (1) \] 其中 \(\hat{t}=w_{t} t+b_{t}\) 和 \(\hat{x} = w_tx_i + b_t\) 是 \(t\) 和 \(x_i\) 的线性变换,其中 \(t\) 和 \(x_i\) 是输入特征 \(\mathbf{X} \in \mathbb{R}^{C \times H \times W}\) 的单个通道中的目标神经元和其他神经元。\(i\) 是空间维度上的索引,\(M = H \times W\) 是该通道上的神经元数目。\(w_t\) 和 \(b_t\) 是变换的权重和偏置。方程( 1 )中的所有值都是标量。当 \(\hat{t} = y_t\) 时,方程( 1 )取得最小值,其他所有的 \(x_i\) 都是 \(y_0\) ,其中 \(y_t\) 和 \(y_0\) 是两个不同的值。通过最小化该方程,方程( 1 )等价于寻找目标神经元 \(t\) 与同一通道内所有其他神经元之间的线性可分性。为了简单起见,我们对 \(y_t\) 和 \(y_0\) 使用了二进制标签(即1和- 1),并且在方程( 1 )中加入了正则项。最终的能量函数为: \[ \begin{aligned} e_{t}\left(w_{t}, b_{t}, \mathbf{y}, x_{i}\right) & =\frac{1}{M-1} \sum_{i=1}^{M-1}\left(-1-\left(w_{t} x_{i}+b_{t}\right)\right)^{2} +\left(1-\left(w_{t} t+b_{t}\right)\right)^{2}+\lambda w_{t}^{2} \end{aligned}\ \ \ \ (2) \] 理论上,每个通道有M个能量函数。通过像SGD这样的迭代求解器来求解所有这些方程在计算上是很麻烦的。幸运的是,方程( 2 )有一个关于 \(w_t\) 和 \(b_t\) 的快速闭式解,可以很容易地得到: \[ w_{t}=-\frac{2\left(t-\mu_{t}\right)}{\left(t-\mu_{t}\right)^{2}+2 \sigma_{t}^{2}+2 \lambda}\ \ \ \ \ \ \ \ \ \ (3) \]
\[ b_{t}=-\frac{1}{2}\left(t+\mu_{t}\right) w_{t}\ \ \ \ \ \ \ \ \ \ \ \ (4) \]
\(\mu_{t}=\frac{1}{M-1} \sum_{i=1}^{M-1} x_{i}\) 和 \(\hat{\sigma}^{2}=\frac{1}{M} \sum_{i=1}^{M}\left(x_{i}-\hat{\mu}\right)^{2}\) 是在该通道除 \(t\) 外的所有神经元上计算的均值和方差。由于式( 3 )和式( 4 )所示的现有解决方案是在单个通道上获得的,因此可以合理地假设单个通道中的所有像素遵循相同的分布。给定这个假设,可以在所有神经元上计算均值和方差,并对该通道(Hariharan et al., 2012)上的所有神经元重用。它可以显著降低计算成本,避免为每个位置迭代计算 μ 和 σ。因此,可以用下面的方法计算最小能量: \[ e_{t}^{*}=\frac{4\left(\hat{\sigma}^{2}+\lambda\right)}{(t-\hat{\mu})^{2}+2 \hat{\sigma}^{2}+2 \lambda} \] 其中 \(\hat{\mu}=\frac{1}{M} \sum_{i=1}^{M} x_{i}\) 以及 \(\hat{\sigma}^{2}=\frac{1}{M} \sum_{i=1}^{M}\left(x_{i}-\hat{\mu}\right)^{2}\) 。
到目前为止,我们推导出一个能量函数,并发现每个神经元的重要性。根据(希利亚德等, 1998),哺乳动物大脑中的注意力调节通常表现为对神经元反应的增益(即,缩放)效应。因此,我们使用缩放运算符而不是添加来进行特征细化。我们模块的整个精化阶段是: \[ \widetilde{\mathbf{X}}=\operatorname{sigmoid}\left(\frac{1}{\mathbf{E}}\right) \odot \mathbf{X} \] 式中:E跨通道和空间维度对所有的 \(e^t_*\) 进行分组,增加sigmoid以限制E中过大的值,不会影响每个神经元的相对重要性,因为sigmoid是单调函数。
源代码
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!