SIoU
论文:SIoU Loss: More Powerful Learning for Bounding Box Regression

Methods
SIoU由四个部分组成
- Angle cost
- Distance cost
- Shape cost
- IoU cost
Angle cost
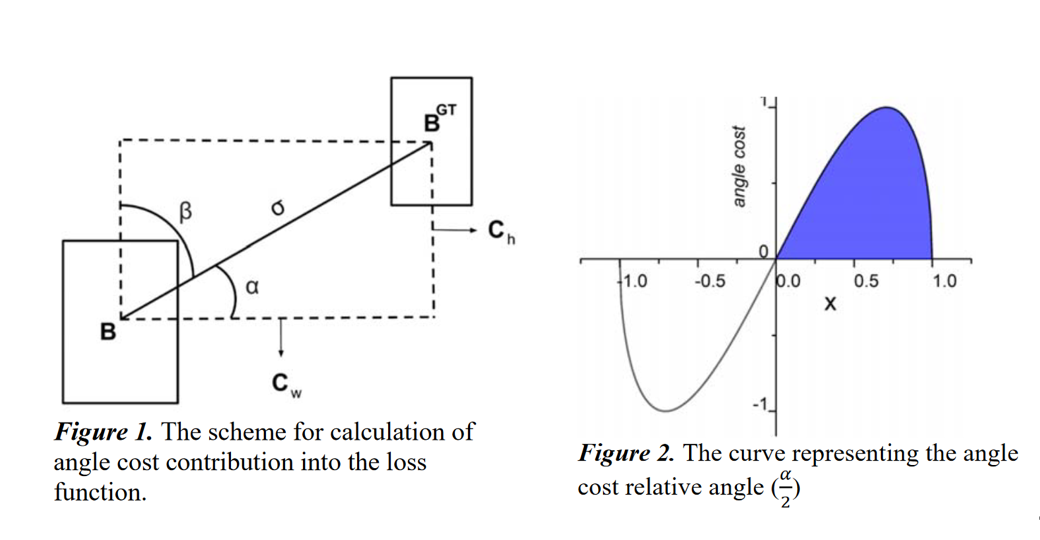
添加这个角度感知的损失函数组件背后的想法是最小化与距离相关的"奇迹"中的变量数量。基本上,模型会尝试先将预测带到X或Y轴(以最接近者为准),然后沿相关轴继续进行。为了实现这一点,收敛的过程如果 \(\alpha \le \frac{\pi}{4}\) 将首先尝试最小化 \(\alpha\) 否则最小化 \(\beta = \frac{\pi}{2} - \alpha\)
为了实现这一点,首先引入并定义了损失函数: \[ \Lambda=1-2 * \sin ^{2}\left(\arcsin (x)-\frac{\pi}{4}\right) \ \ \ \ where \ \ \ x=\frac{c_{h}}{\sigma}=\sin (\alpha) \]
\[ \begin{array}{c} \sigma=\sqrt{\left(b_{c_{x}}^{g t}-b_{c_{x}}\right)^{2}+\left(b_{c_{y}}^{g t}-b_{c_{y}}\right)^{2}} \\ c_{h}=\max \left(b_{c_{y}}^{g t}, b_{c_{y}}\right)-\min \left(b_{c_{y}}^{g t}, b_{c_{y}}\right) \end{array} \]
Distance cost
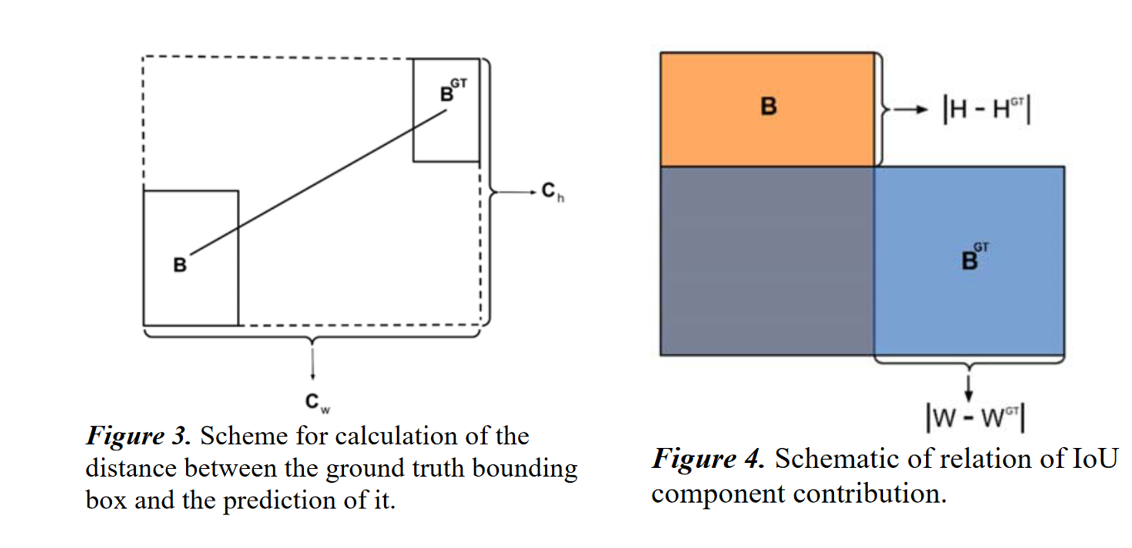
考虑到上文定义的角度成本,重新定义了距离成本: \[ \Delta=\sum_{t=x, y}\left(1-e^{-\gamma \rho_{t}}\right) \] where \[ \rho_{x}=\left(\frac{b_{c_{x}}^{g t}-b_{c_{x}}}{c_{w}}\right)^{2}, \rho_{y}=\left(\frac{b_{c_{y}}^{g t}-b_{c_{y}}}{c_{h}}\right)^{2}, \gamma=2-\Lambda \] 可以看到,当α→0时,距离成本的贡献急剧下降。反之,α 越接近 \(\frac{\pi}{4}\),Δ越大,贡献越大。随着角度的增加,问题变得更加困难。因此随着角度的增大,\(\gamma\) 优先于距离值。注意,当α→0时,距离成本将成为常规
Shape cost
Shape cost定义为: \[ \Omega=\sum_{t=w, h}\left(1-e^{-\omega_{t}}\right)^{\theta} \] where \[ \omega_{w}=\frac{\left|w-w^{g t}\right|}{\max \left(w, w^{g t}\right)}, \omega_{h}=\frac{\left|h-h^{g t}\right|}{\max \left(h, h^{g t}\right)} \] 并且θ的值定义了形状代价的大小,其值对于每个数据集是唯一的。在这个方程中θ的值是一个非常重要的项,它控制着形状的代价应该被关注的程度。如果θ的值设置为1,它会立即优化形状,从而损害形状的自由移动。为了计算θ的值,对每个数据集使用遗传算法,实验中 θ 的值接近于4,作者为这个参数定义的范围是2到6。
最后我们定义损失函数; \[ L_{b o x}=1-I o U+\frac{\Delta+\Omega}{2} \]
\[ I o U=\frac{\left|B \cap B^{G T}\right|}{\left|B \cup B^{G T}\right|} \]
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!