distillation
Classification
Knowledge Distillation via the Target-aware Transformer (CVPR 2022)
目前不足:
- 感受野对模型表征能力影响十分重要,这种差异是目前一对一匹配蒸馏法导致次优结果的潜在原因。
改进:
- 我们提出通过target-aware transformer(TaT)进行知识提炼,使全体学生分别模仿教师的各个空间组件(one-to-all)。这样,我们就能提高匹配能力,从而改善知识提炼的性能。
- 我们提出了分层蒸馏法,以转移局部特征和全局依赖性,而不是原始特征图。这样,我们就能将提出的方法应用于因特征图规模庞大而计算负担沉重的应用中。
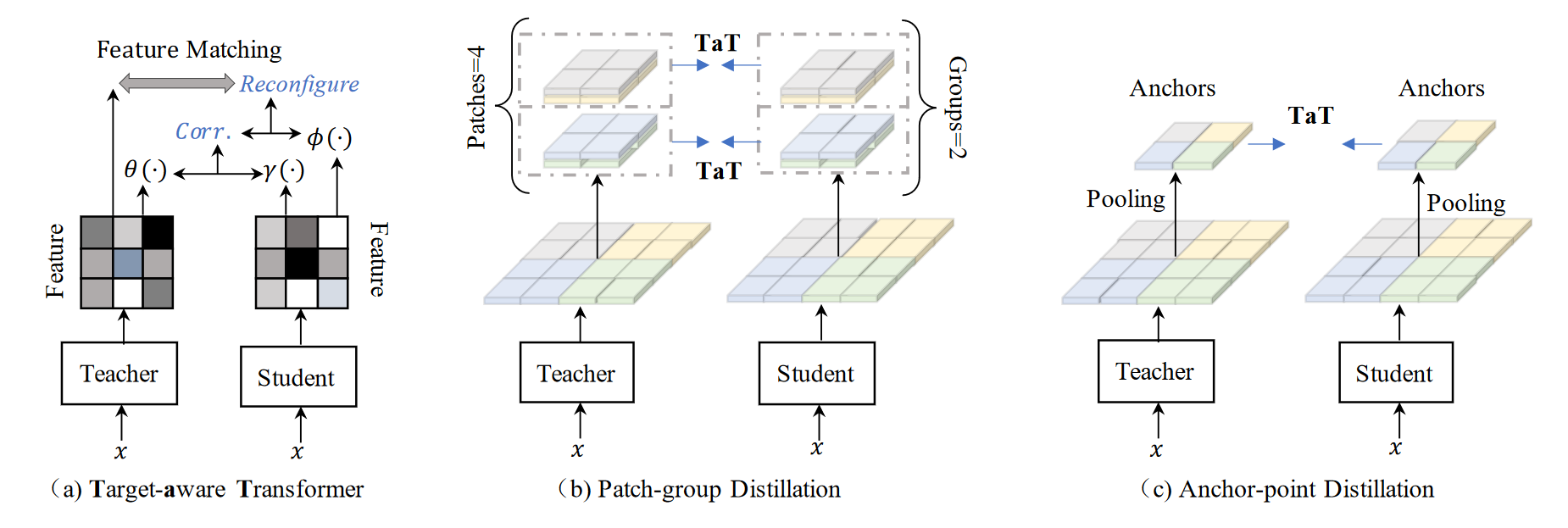
由于教师网络的特征图通常包含更多的层和更大的特征通道,与学生网络相比,同一像素位置的空间信息包含更丰富的语义信息。为此,我们提出了一个一对一的空间匹配知识提炼管道,让教师的每个特征位置都能以动态的方式教授整个学生的特征。 \[ \begin{aligned} W^{i} & =\sigma\left(\left\langle f_{1}^{s}, f_{i}^{t}\right\rangle,\left\langle f_{2}^{s}, f_{i}^{t}\right\rangle, \ldots,\left\langle f_{N}^{s}, f_{i}^{t}\right\rangle\right) \\ & =\left[w_{1}^{i}, w_{2}^{i}, \ldots, w_{N}^{i}\right] \end{aligned} \] 将这些相关语义汇总到所有组件中,我们就得到了结果: \[ f_{i}^{s^{\prime}}=w_{1}^{i} \times f_{1}^{s}+w_{2}^{i} \times f_{2}^{s}+\cdots+w_{N}^{i} \times f_{N}^{s} \] 两个公式可以合为一个矩阵乘法:\(f^{s^{'}}_i=\sigma(f^s\cdot f^t_i)\cdot f^s\)
为了方便训练,我们引入了参数方法,对学生特征和教师特征进行了额外的线性变换。我们发现,在消融研究中,参数版本比非参数版本表现更好。 \[ f^{s^{\prime}}=\sigma\left(\gamma\left(f^s\right) \cdot \theta\left(f^t\right)^{\top}\right) \cdot \phi\left(f^s\right) \] 最后TaT的损失函数就为: \[ \mathcal{L}_{\mathrm{TaT}}=\left\|f^{s^{\prime}}-f^t\right\|_2 \] 但是TaT的计算量还是很大,所以通过Patch-group Distillation和Anchor-point Distillation减少计算量。
- Patch-group Distillation通过将特征图分割成Patch然后n个Patch为一组,在各组之间计算TaT损失
- 上述算法对于远距离的感知性较差。Anchor-point Distillation将特征图进行池化采样成小特征图进行计算TaT损失
最后总的Loss为: \[ \mathcal{L}_{\mathrm{Seg}}=\alpha \mathcal{L}_{\mathrm{CE}}+\delta \mathcal{L}_{\mathrm{TaT}}^{\mathcal{P}}+\zeta \mathcal{L}_{\mathrm{TaT}}^{\mathcal{A}} \]
A Fast Knowledge Distillation Framework for Visual Recognition(ECCV 2022)
不足:
- 蒸馏方法消耗资源大,因为每次都要遍历一遍教师网络。因为现在许多训练方式包含数据增强,我们无法将中间的软标签进行重复利用
- ReLabel 被提出来存储来自预先训练的强教师的全局标签图注释,以便 RoI align 重新利用,而无需重复通过教师网络。(1)但是全局标签图是通过输入全局图像获得的,它不能像在输入空间中采用随机裁剪-调整操作的蒸馏过程那样完全反映软分布。(2)RoI 对齐不能保证分布与教师转发的分布完全一致。
创新点:
地址:https://github.com/szq0214/FKD
Improved Feature Distillation via Projector Ensemble(NeurIPS)
不足:
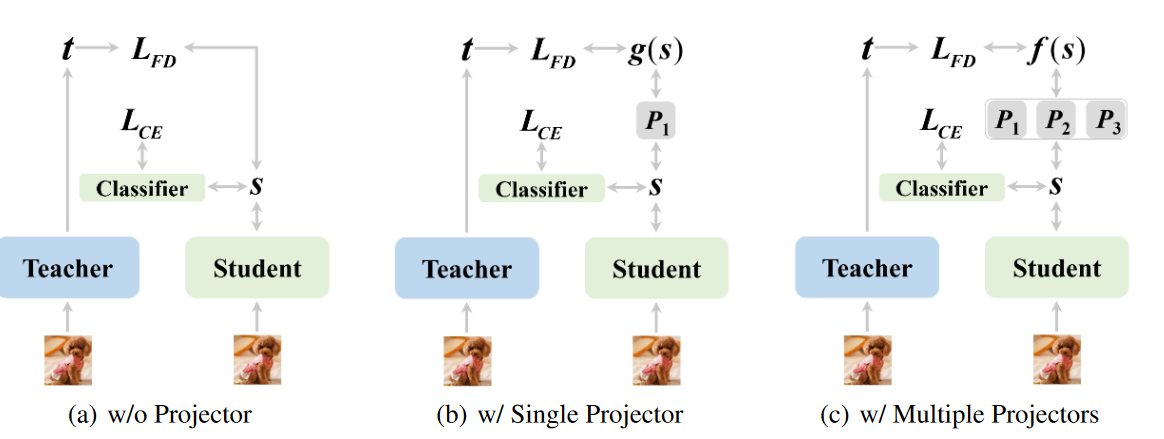
- 不使用projector直接进行蒸馏学习的话,很容易造成学生的过拟合
创新点:
- 受使用projector可以提升性能的启发,作者使用多个映射器进行蒸馏学习
Feature Distillation as Multi-task Learning
由于蒸馏方法对超参数和老师-学生组合的变化很敏感,额外的目标会增加系数调整的训练成本。为了减轻这个问题,作者简单的使用如下Direction Alignment(DA)损失进行特征蒸馏: \[ \mathcal{L}_{DA}=\frac1{2b}\sum_{i=1}^b||\frac{g(s_i)}{||g(s_i)||_2}-\frac{t_i}{||t_i||_2}||_2^2=1-\frac1b\sum_{i=1}^b\frac{\langle g(s_i),t_i\rangle}{||g(s_i)||_2||t_i||_2}, \]
Improved Feature Distillation with Projector Ensemble
上一节主要讲述projector确实可以提升学生的学习能力,收到这个启发,作者使用projector组合进行进一步提升。主要有两个动机:
- 多个projector具有不同的初始化会提供不同的转换特征,这有助于学生的泛化
- 因为在projector中使用ReLU,所以学生特征可能出现0,但是教师中使用了池化层,不太可能出现0。所以学生和教师的特征分布会有差距,所以使用多个projector可以进行权衡。
使用了多个projector后,Modified Direction Alignmen(MDA)loss如下: \[ \mathcal{L}_{MDA}=1-\frac1b\sum_{i=1}^b\frac{\langle f(s_i),t_i\rangle}{||f(s_i)||_2||t_i||_2} \] 其中 \(f(\cdot)\) 就是多个projector。最后总的loss如下: \[ \mathcal{L}_{total}=\mathcal{L}_{CE}+\alpha\mathcal{L}_{MDA} \]
Exploring Inter-Channel Correlation for Diversity-preserved Knowledge Distillation(ICCV 2023)
不足:
- 以往的知识蒸馏方法忽略了特征的多样性和同质性,导致学生网络无法学习到教师网络的内在特征分布和丰富性。
创新点:
- 提出了一种基于通道间相关性的知识蒸馏方法,能够有效地传递教师网络的特征多样性和同质性,提高学生网络的泛化能力和表达能力
- 提出了一种网格级别的通道间相关性蒸馏方法,能够稳定地进行密集预测任务的知识蒸馏,并保留空间信息。
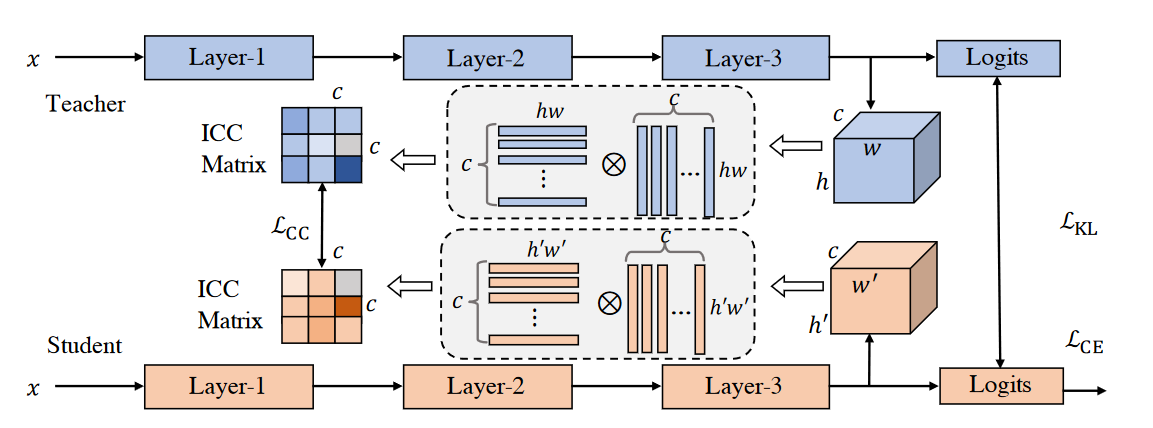
Formulation
在本节中,我们介绍通道间相关性的公式。给定两个通道,相关性度量应该返回反映它们相关性的值。一个比较高的值代表同源,否则相反。最终,所有相关性度量按顺序收集以表示通道的整体多样性。通道间相关性可以被表示为: \[ \mathcal{G}_{m,n}^{F^T}=K(\mathrm{v}(F_m^T),\mathrm{v}(F_n^T)) \] 其中 \(F^T_m \in \mathbb{R}^{h \times w}\) 代表第m个通道,v() 将2D特征图向量化为长度hw的向量,K()是衡量输入相关性的函数,其中使用内积。公式中无论通道的空间维度如何,都会返回一个标量,这可以用矩阵乘法的方式重写,形成我们的ICC矩阵: \[ \mathcal{G}^{F^T}=\mathrm{f}(F^T)\cdot\mathrm{f}(F^T)^\top \] 其中f()用于将空间维度拉平。不管空间维度h和w如何,ICC矩阵都是 \(c \times c\) 的大小。根据经验设置,我们在学生特征的基础上添加一个线性变换层 \(C_l\) ,它由一个具有1x1的卷积核的卷积层和一个没有激活函数的BN层组成,用来匹配学生和老师的维度不匹配。我们对学生和老师的ICC矩阵之间的L2距离进行惩罚,让学生获得相似的特征多样性: \[ \mathcal{L}_{CC}=\frac1{c^2}\|\mathcal{G}^{C^{(F^S)}_l}-\mathcal{G}^{F^T}\|_2^2 \] 我们将上述方法称为ICKD-C,它主要是为图像分类而开发的。最后,我们方法的目标由下式给出: \[ \mathcal{L}_{\mathrm{ICKD-C}}=\mathcal{L}_{\mathrm{CE}}+\beta_1\mathcal{L}_{\mathrm{KL}}+\beta_2\mathcal{L}_{\mathrm{CC}}, \]
Grid-Level Inter-Channel Correlation
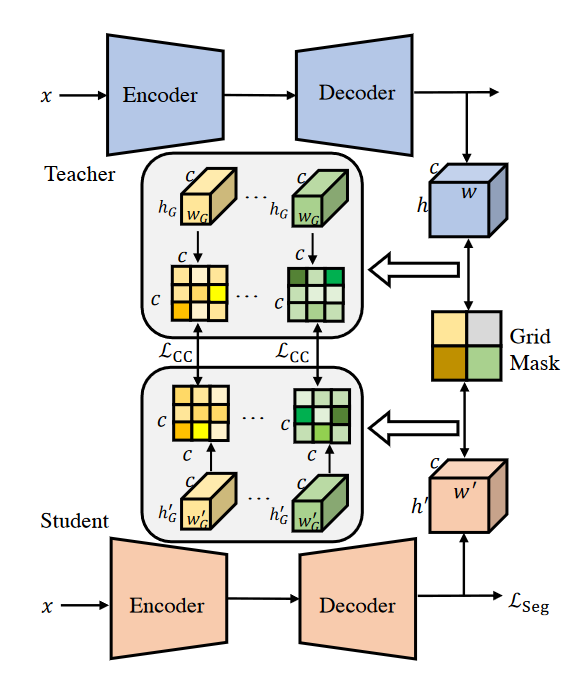
受分治法的启发,我们寻求分割特征图,然后单独进行知识蒸馏。我们沿着像素位置将特征分割成n x m的部分。每个部分的ICC都是单独计算的。 \[ \begin{gathered} \mathcal{G}^{F_{(i,j)}^T}=\text{f}(F_{(i,j)}^T)\cdot\text{f}(F_{(i,j)}^T)^\top, \\ \mathcal{G}^{F_{(i,j)}^{S}}=\mathrm{f}(F_{(i,j)}^{S})\cdot\mathrm{f}(F_{(i,j)}^{S})^{\top}, \\ \mathcal{L}_{\mathrm{CC}}^{n\times m}=\frac1{n\times m\times c^2}\sum_i^n\sum_j^m||\mathcal{G}^{F_{(i,j)}^T}-\mathcal{G}^{F_{(i,j)}^S}||_2^2. \end{gathered} \] 我们使用Grid Mask将整个特征均匀地划分为不同的组。尽管空间维度发生了变化,但得到的ICC矩阵的大小始终取决于通道数,即c。此外,网格划分还有助于提取更多的空间和局部信息,这有利于正确分类像素进行语义分割。这个变体被称为ICKD - S。最后,语义分割的目标被表述为: \[ \mathcal{L}_{\mathrm{ICKD-S}}=\mathcal{L}_{\mathrm{Seg}}+\alpha\mathcal{L}_{\mathrm{CC}}^{n\times m}, \]
Object Detection
IMPROVE OBJECT DETECTION WITH FEATURE-BASED KNOWLEDGE DISTILLATION: TOWARDS ACCURATE AND EFFICIENT DETECTORS (ICLR 2021)
KD在目标检测方向的应用受限主要是因为如下两个原因
- 前后背景的像素点数量不平衡
- 像素间的关联性缺少一定的蒸馏
对应的解决策略如下:
- 既然存在不平衡关系,那我直接只针对这些bbox的区域做不就好了吗。有些是直接二值mask过滤、有的是将二值soft成高斯分布的形式
- 采用Non-Local算子产生attention map,针对attention map计算L2损失回归
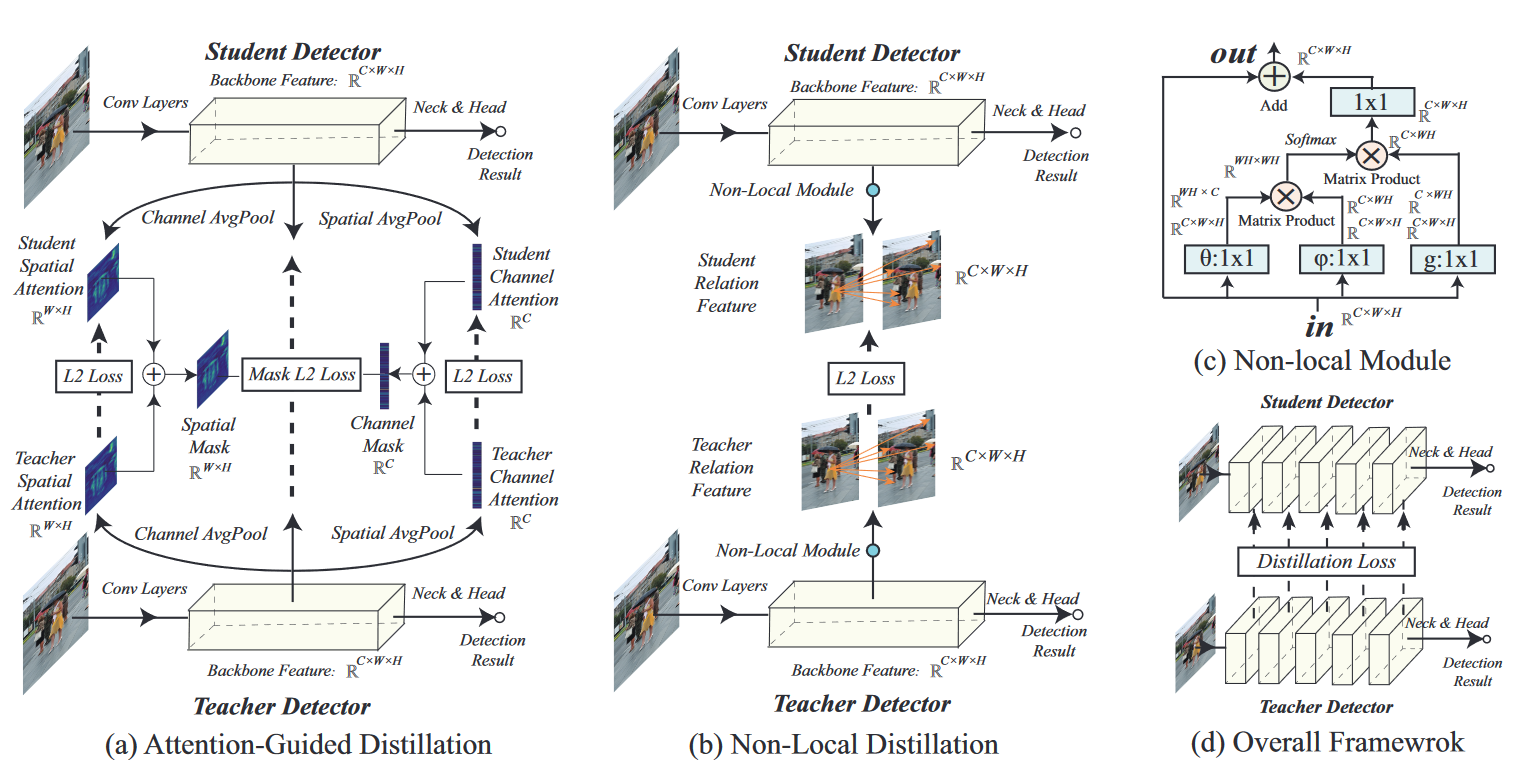
ATTENTION-GUIDED DISTILLATION
那么,空间注意力图和通道注意力图的生成就等同于找到映射函数 \(\mathcal{G}^s: \mathbb{R}^{C, H, W} \rightarrow \mathbb{R}^{H, W}\) 和 \(\mathcal{G}^c: \mathbb{R}^{C, H, W} \rightarrow \mathbb{R}^C\)。由于特征中每个元素的绝对值都意味着其重要性,因此我们通过对通道维度的绝对值求和来构建 \(\mathcal{G}^s\),并通过对宽度和高度维度的绝对值求和来构建 \(\mathcal{G}^c\),具体公式为\(\mathcal{G}^c(A)=\frac{1}{H W} \sum_H^{i=1} \sum_W^{j=1}\left|A_{\cdot, i, j}\right|\)和\(\mathcal{G}^s(A)=\frac{1}{C} \sum_C^{k=1}\left|A_{k,, \cdot}\right|\)。然后,将教师和学生Detector的注意力图相加,就可以得到注意力引导蒸馏法中使用的空间注意力掩码 \(M^s\) 和通道注意力掩码 \(M^c\),公式为\(M^s=H W \cdot \operatorname{softmax}\left(\left(\mathcal{G}^s\left(A^{\mathcal{S}}\right)+\mathcal{G}^s\left(A^{\mathcal{T}}\right)\right) / T\right)\)和\(M^c=C\cdot\text{softmax}(\mathcal{G}^c(A^{\mathcal{S}})+\mathcal{G}^c(A^{\mathcal{T}}))/T)\)。注意力引导蒸馏损失 \(\mathcal{L}_{AGD}\) 由两部分组成--注意力转移损失 \(\mathcal{L}_{AT}\) 和注意力屏蔽损失 \(\mathcal{L}_{AM}\)。 \(\mathcal{L}_{AT}\) 鼓励学生模型模拟教师模型的空间和通道注意力: \[ \mathcal{L}_{AT}=\mathcal{L}_2(\mathcal{G}^s(A^{\mathcal{S}}),\mathcal{G}^s(A^{\mathcal{T}}))+\mathcal{L}_2(\mathcal{G}^c(A^{\mathcal{S}}),\mathcal{G}^c(A^{\mathcal{T}})) \] \(\mathcal{L}_{AM}\)鼓励学生模仿教师模型的特征: \[ \begin{aligned}\mathcal{L}_{AM}&=\left(\sum_{k=1}^C\sum_{i=1}^H\sum_{j=1}^W(A_{k,i,j}^T-A_{k,i,j}^\mathcal{S})^2\cdot M_{i,j}^s\cdot M_k^c\right)^{\frac{1}{2}}\end{aligned} \]
NON-LOCAL DISTILLATION
使用NON-LOCAL模块来提取全局信息,最后Loss: \[ \mathcal{L}_{NLD}=\mathcal{L}_{2}(r^{\mathcal{S}},r^{\mathcal{T}}) \]
OVERALL LOSS FUNCTION
\[ \mathcal{L}_{Distill}(A^\mathcal{T},A^\mathcal{S})=\underbrace{\alpha\cdot\mathcal{L}_{AT}+\beta\cdot\mathcal{L}_{AM}}_{\text{Attention-guided distillation}}+\underbrace{\gamma\cdot\mathcal{L}_{NLD}.}_{\text{Non-local distillation}} \]
Localization Distillation for Object Detection (TPAMI)
还没看懂,后面再看
General Instance Distillation for Object Detection (CVPR 2021)
不足:
- 此外,目前的检测蒸馏方法不能同时在多个检测框架中很好地发挥作用,例如两阶段、一阶段、无锚方法。
贡献:
- 将General Instance(GI)定义为蒸馏目标,可有效提高检测模型的蒸馏效果。
- 在 GI 的基础上,我们首先引入基于关系的知识,对检测任务进行提炼,并将其与基于反应和特征的知识进行整合,从而使学生超越教师。
- 我们的方法对各种检测框架具有稳健的泛化性
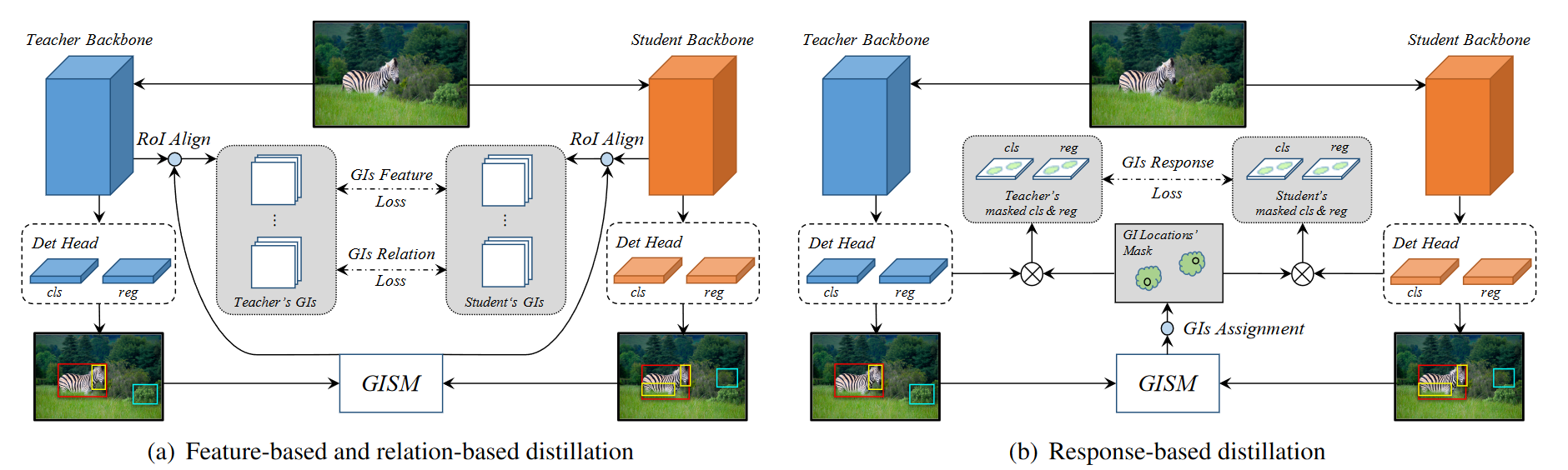
General Instance Selection Module
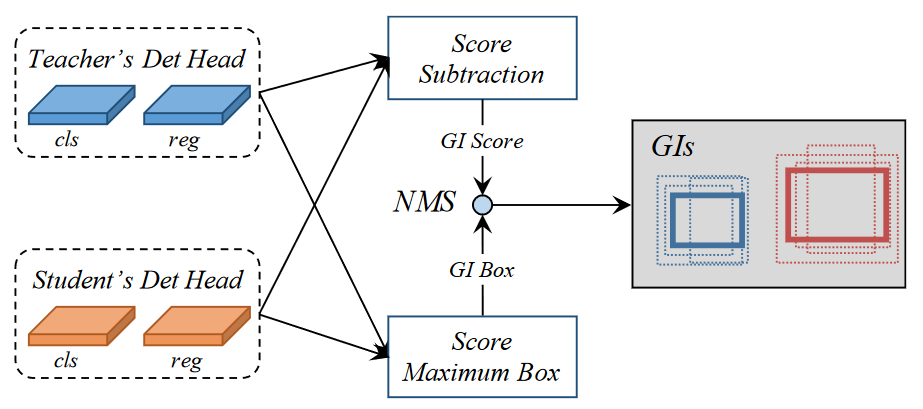
为了量化每个实例的差异以及选择用于蒸馏的判别实例,提出了两个指标:GI score和GI box。为了节省训练时的计算资源,我们只需计算分类得分的 L1 距离作为 GI score,并选择得分较高的方框作为 GI box(针对每一个回归框,作者通过比较tea与stu回归框的所有分类得分差异最大的那个作为当前框的差异分数)。上图展示了生成 GI 的过程,每个预测实例 r 的得分和方框定义如下: \[ \begin{aligned} P_{GI}^{r}& =\max_{0<c\leq C}\left|P_t^{rc}-P_s^{rc}\right|, \\ B_{GI}^r& =\left\{\begin{array}{cc}B_t^r,&\max_{0<c\leq C}P_t^{rc}>\max_{0<c\leq C}P_s^{rc}\\B_s^r,&\max_{0<c\leq C}P_t^{rc}\leq\max_{0<c\leq C}P_s^{rc}\end{array}\right., \\ \text{GI}& =NMS(P_{GI},B_{GI}), \end{aligned} \] 其中\(P_{GI}\)和\(B_{GI}\)分别为GI score和GI box。对与one-stage来说\(P_t\)和\(P_s\)就是教师和学生模型的预测分类得分,对于two-stage来说\(P\)就是RPN预测的目标得分。同时,\(B_t\)和\(B_s\)就是预测的目标框了。R 是预测框的数量,C 是类别的数量。r、c 是 R、C 维度中的索引。最后使用NMS来消除冗余的重叠实例。此外,在每幅图像中,我们只选择得分最高的 K 个实例作为蒸馏的最终 GI。
Feature-based Distillation
由于 FPN 结合了多个骨干层的特点,我们直观地选择 FPN 进行蒸馏。具体来说,我们根据每个 GI 方框的不同大小,对匹配 FPN 层的特征进行裁剪。鉴于检测任务中目标大小的差异很大,直接进行像素化提炼会使模型更倾向于学习大型目标。因此,我们采用 ROIAlign 算法,将不同大小的 GI 特征调整为相同大小,然后进行蒸馏,对每个目标一视同仁。基于特征的蒸馏损失如下: \[ \begin{gathered}L_{Feature}=\frac1K\sum_{i=1}^K\left\|t_i-s_i^{\prime}\right\|_2^2,\\s^{\prime}=f_{adapt}(s),\end{gathered} \] K是第一部分GISM挑选出来的GI数量。第二个公式是线性适应方法令学生特征图映射到和教师相同维度。
Relation-based Distillation
在这里,我们使用欧氏距离来衡量实例的相关性,并使用 L1 距离来传递知识。我们还利用 GI 之间的相关性信息来提炼从教师到学生的知识。损失表达式如下: \[ \begin{aligned} L_{Relation}& \begin{aligned}=\sum_{(i,j)\in\mathbb{K}^2}l(\frac{1}{\phi(t)}\|t_i-t_j\|_2,\frac{1}{\phi(s)}\|s'_i-s'_j\|_2),\end{aligned} \\ \phi(x)& =\frac1{|\mathbb{K}^2|}\sum_{(i,j)\in\mathbb{K}^2}\|x_i-x_j\|_2, \end{aligned} \] \(\phi(\cdot)\)是归一化因子。\(l\) 是 L1 loss。
Response-based Distillation
对检测头的整个输出进行提炼会损害学生模型的性能。 这可能是由于检测任务中正负样本的不平衡以及过多的负样本带来的噪声造成的。最近,一些检测蒸馏方法只对检测头的正样本进行蒸馏,而忽略了具有判别能力的负样本的正则化效应。因此,我们根据选定的 GI 为分类分支和回归分支设计了蒸馏掩码,事实证明这比仅使用 GT 标签作为蒸馏掩码更有效。
然而,由于不同模型对探测头输出的定义不同,我们提出了一个针对不同模型对探测头进行蒸馏的通用框架。首先,基于 GI 的蒸馏掩码计算如下: \[ M=F_{Assign}(GIs), \] F是标签分配算法。例如,对于 RetinaNet,我们使用锚点和 GI 之间的 IoU 来确定是否屏蔽。对于 FCOS,GI 以外的所有输出都是屏蔽的。于是Loss为: \[ \begin{aligned}L_{Response}=\frac{1}{N_m}\sum_{i=1}^{R}M_i\left(\alpha L_{cls}\left(y_t^i,y_s^i\right)+\beta L_{reg}\left(r_t^i,r_s^i\right)\right)\\ N_m=\sum_{i=1}^RM_i \end{aligned} \] 其中y是分类头输出,r是回归头输出。
Overall loss function
\[ \begin{aligned}L&=L_{GT}+\lambda_1L_{Feature}+\lambda_2L_{Relation}+\lambda_3L_{Response}\end{aligned} \]
Distilling Object Detectors via Decoupled Features (CVPR 2021)
不足:
- 以往的paper都没有使用背景区域进行蒸馏学习,只使用了目标区域
创新点:
- 使用解耦的目标区域和背景区域进行蒸馏学习
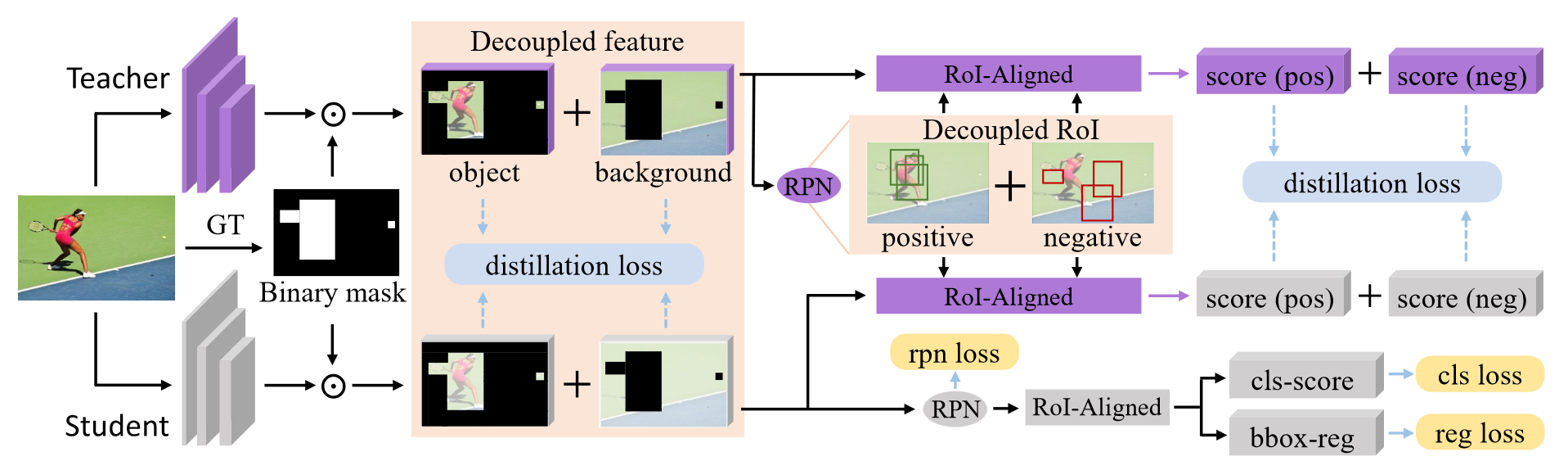
Decouple Intermediate Features in Distillation
我们得出的结论是,中间特征中的背景区域可以补充目标区域,进一步帮助学生检测器的训练。利用ground-truth来生成二值化的掩码,随后使用二值化的掩码来区分前景和背景,然后解耦的进行损失值的计算。 \[ \begin{aligned}&\mathcal{L}_{fea}=\frac{\alpha_{obj}}{2N_{obj}}\sum_{h=1}^{H}\sum_{w=1}^{W}\sum_{c=1}^{C}M_{h,w}(\phi(\mathcal{S}_{h,w,c})-\mathcal{T}_{h,w,c})^2\\&+\frac{\alpha_{bg}}{2N_{bg}}\sum_{h=1}^{H}\sum_{w=1}^{W}\sum_{c=1}^{C}(1-M_{h,w})(\phi(\mathcal{S}_{h,w,c})-\mathcal{T}_{h,w,c})^2,\end{aligned} \]
Decouple Region Proposals in Distillation
在蒸馏检测头时将区域建议分为positive建议和negative建议,所以还是对教师和学生的预测结果进行软化: \[ \begin{aligned}p^{s,T_{obj}}(c\mid\theta^s)&=\frac{exp(z_c^s/T_{obj})}{\sum_{j=1}^Cexp(z_j^s/T_{obj})},c\in Y\\p^{t,T_{obj}}(c\mid\theta^t)&=\frac{exp(z_c^t/T_{obj})}{\sum_{j=1}^Cexp(z_j^t/T_{obj})},c\in Y\end{aligned} \] 最后就进行positive和negative的损失计算: \[ \begin{gathered} \begin{aligned}\mathcal{L}_{cls}&=\frac{\beta_{obj}}{K_{obj}}\sum_{i=1}^{K}b_i\mathcal{L}_{KL}(p_i^{s,T_{obj}},p_i^{t,T_{obj}})\end{aligned} \\ +\frac{\beta_{\boldsymbol{b}g}}{K_{\boldsymbol{b}g}}\sum_{i=1}^K{(1-b_i)\mathcal{L}_{KL}(p_i^{s,T_{\boldsymbol{b}g}},p_i^{t,T_{\boldsymbol{b}g}})} \\ \begin{aligned}\mathcal{L}_{KL}(p^{s,T},p^{t,T})&=T^2\sum_{c=1}^Cp^{t,T}(c|\theta^t)\log\frac{p^{t,T}(c|\theta^t)}{p^{s,T}(c|\theta^s)}\end{aligned} \end{gathered} \]
Instance-Conditional Knowledge Distillation for Object Detection (NIPS2021)
不足:
- 许多方法会忽略信息量大的上下文区域,或涉及缜密的决策
- 虽然注意力能为辨别区域提供固有提示,但激活与检测知识之间的关系仍不明确。
创新点:
- 我们设计了一个条件解码模块来定位知识,每个实例之间的相关性由实例感知注意力来计算
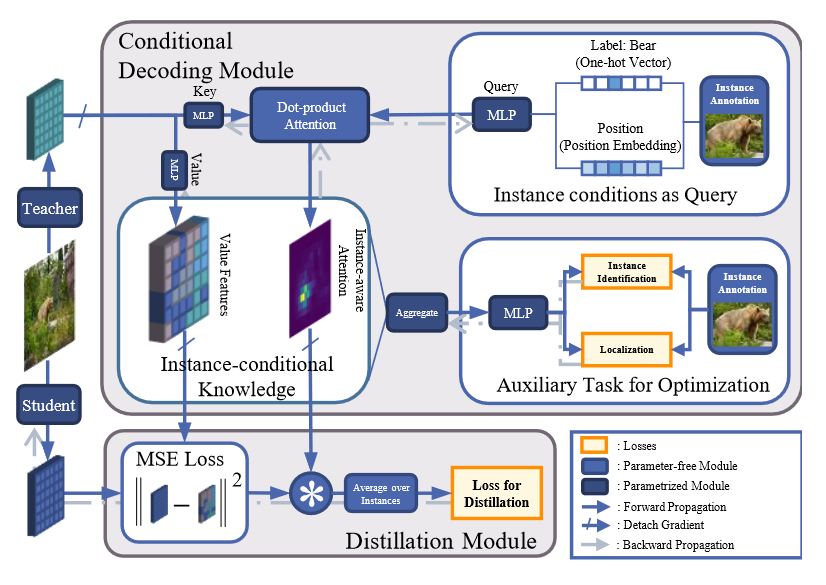
Overview
为了促进KD,作者提出在教师和学生之间传输实例条件知识,Loss为: \[ \mathcal{L}_{distill}=\sum_{i=1}^N\mathcal{L}_d(\kappa_i^\mathcal{S},\kappa_i^\mathcal{T}) \] 其中\(\kappa_i^{\mathcal{T}}=\mathcal{G}(\mathcal{T}, y_i)\),\(\mathcal{G}\)是实例条件解码模块,由辅助loss进行优化。
Instance-conditional Knowledge
实例条件知识由两部分计算得出(1) 无条件知识 (2) 实例条件
无条件知识 \(\mathcal{T}\) , 表示教师探测器提供的所有信息。将多尺度特征表示为 \(\mathcal{T}=\{X_p \in \mathbb{R}^{D\times H_p\times W_p}\}_{p\in \mathcal{P}}\) ,其中 \(\mathcal{P}\) 是空间上的分辨率,D 是维度。沿着空间维度方向对不同尺度的表征进行concat,我们就会获得 \(A^T\in \mathbb{R}^{L \times D}\) ,其中 \(L=\sum_{p \in \mathcal{P}}H_pW_p\) 是各尺度像素总数之和
实例条件最初描述的是人类观察到的物体,用 \(\mathcal{Y} = \{y_i\}^N_{i=1}\) 表示,其中 N 是物体编号,\(y_i = (c_i, b_i)\) 是第 i 个实例的注释,包括类别 \(c_i\) 和框位置 \(b_i = (x_i, y_i, w_i, h_i)\),其中指定了定位和尺寸信息。
为了为每个实例生成可学习的嵌入,注释被映射到隐藏空间中的查询特征向量 \(q_i\),该向量指定了收集所需知识的条件: \[ \mathbf{q}_i=\mathcal{F}_q(\mathcal{E}(\mathrm{y}_i)),\mathrm{~}\mathbf{q}_i\in\mathbb{R}^D \] 其中 \(\mathcal{E} (\cdot)\) 是一个编码方法,以及 \(\mathcal{F}_q\) 是一个MLP
我们通过测量相关反应,从给定 \(q_i\)的 \(\mathcal{T}\) 中检索知识。通过多头注意力机制进行计算得出。 \[ \begin{aligned} &\mathrm{K}_{j}^{\mathcal{T}}&& =\mathcal{F}_j^k(\mathrm{A}^{\mathcal{T}}+\mathcal{F}_{pe}(\mathrm{P})),\text{ K}_j^{\mathcal{T}}\in\mathbb{R}^{L\times d} \\ &\mathrm{V}_j^{\mathcal{T}}&& =\mathcal{F}_j^v(\mathrm{A}^{\mathcal{T}}),\text{ V}_j^{\mathcal{T}}\in\mathbb{R}^{L\times d} \\ &\mathbf{q}_{ij}&& =\mathcal{F}_j^q(\mathbf{q}_i),\mathbf{q}_{ij}\in\mathbb{R}^d \\ &\mathbf{m}_{ij}&& =softmax(\frac{\mathrm{K}_j^T\mathbf{q}_{ij}}{\sqrt{d}}),\mathbf{m}_{ij}\in\mathbb{R}^L \end{aligned} \]
Auxiliary Task
等下次再看,不太懂
Focal and Global Knowledge Distillation for Detectors (CVPR2022)
不足:
- 将前景和背景不进行解耦一起进行蒸馏结果是最差的,这一现象表明,特征图的不均匀差异会对蒸馏产生负面影响。
- 再往深处想,不仅前景和背景之间存在负面影响,像素和通道之间也存在负面影响。
- 缺乏对全局信息的提取。
创新点:
- 提出focal蒸馏。在分离前景和背景的同时,焦点提炼还能计算出教师特征中不同像素和通道的关注度,让学生关注教师的关键像素和通道。
- 提出global蒸馏。我们利用 GcBlock 提取不同像素之间的关系,然后将其从教师提炼到学生。
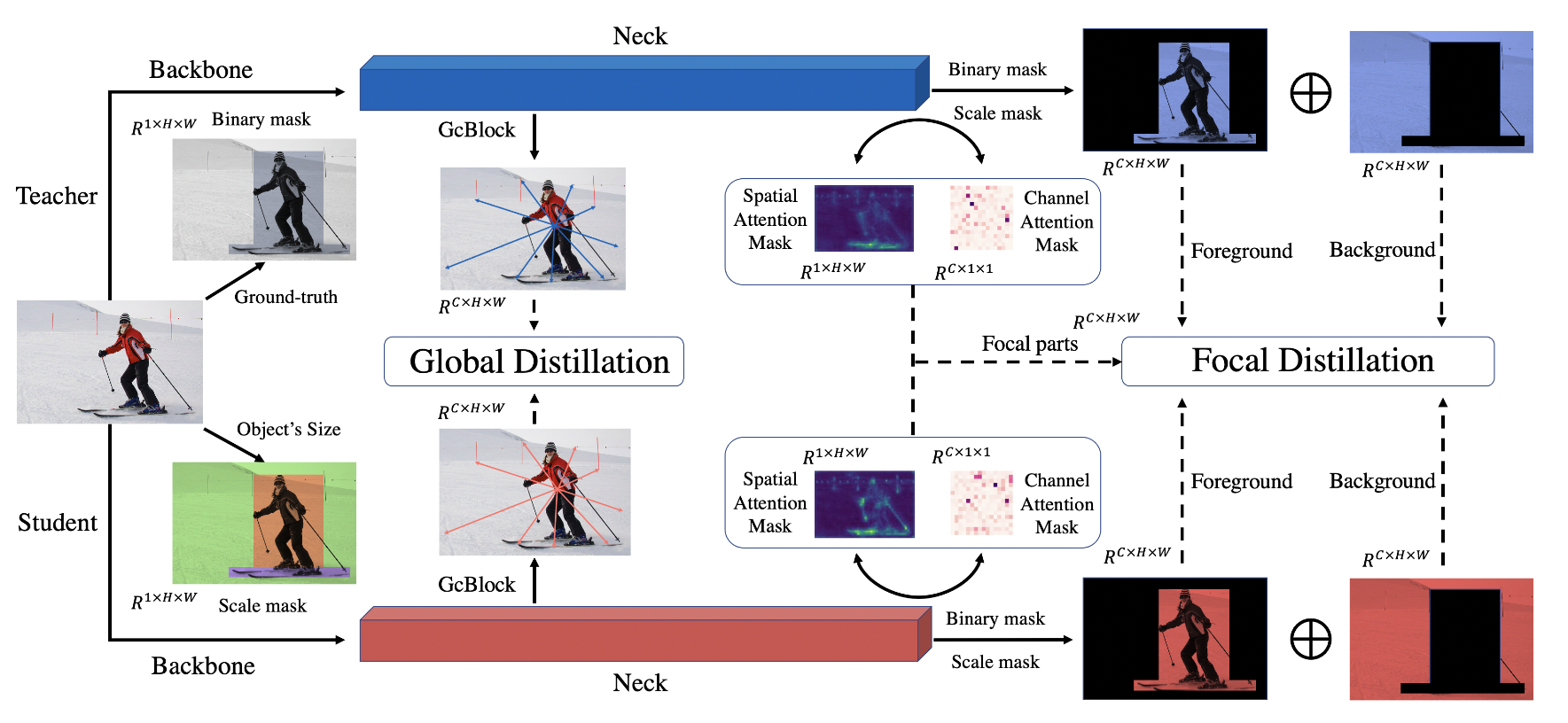
Focal Distillation
针对前景和背景不平衡的问题,我们提出了焦点蒸馏法来分离图像,引导学生关注关键像素和通道。对于蒸馏区域的对比如下图所示:
首先还是利用ground-truth来得到二值化掩码M。在不同的图像中,像素数量和前景与背景的比例差异很大。因此,为了对不同目标一视同仁,平衡前景和背景的损失,我们将比例掩码 S 设置为: \[ \begin{aligned}S_{i,j}&=\begin{cases}\frac1{H_rW_r},&\mathrm{if~}\left(i,j\right)\in r\\\frac1{N_{bg}},&\mathrm{Otherwise}&\end{cases}\\\\N_{bg}&=\sum_{i=1}^H\sum_{j=1}^W(1-M_{i,j})\end{aligned} \] 其中r就是ground-truth。如果一个像素属于不同的目标,我们会选择最小的方框来计算 S。
随后先选择焦点像素和通道,然后得到相应的注意力掩码。我们分别计算不同像素和不同通道的绝对平均值: \[ \begin{aligned}G^S(F)&=\frac1C\cdot\sum_{c=1}^C|F_c|\\\\G^C(F)&=\frac1{HW}\cdot\sum_{i=1}^H\sum_{j=1}^W|F_{i,j}|\end{aligned} \] 然后得到注意力机制掩码: \[ \begin{aligned}A^S(F)&=H\cdot W\cdot softmax\big(G^S(F)/T\big)\\\\A^C(F)&=C\cdot softmax\big(G^C(F)/T\big)\end{aligned} \] 得到特征损失函数: \[ \begin{aligned}L_{fea}&=\alpha\sum_{k=1}^C\sum_{i=1}^H\sum_{j=1}^WM_{i,j}S_{i,j}A_{i,j}^SA_k^C\left(F_{k,i,j}^T-f(F_{k,i,j}^S)\right)^2\\&+\beta\sum_{k=1}^C\sum_{i=1}^H\sum_{j=1}^W(1-M_{i,j})S_{i,j}A_{i,j}^SA_k^C\left(F_{k,i,j}^T-f(F_{k,i,j}^S)\right)^2\end{aligned} \] 此外,我们还利用注意力损失使学生检测器模仿教师检测器的空间和通道注意力掩码,其公式为: \[ L_{at}=\gamma\cdot\left(l(A_t^S,A_S^S)+l(A_t^C,A_S^C)\right) \] 最后的Focal loss为: \[ L_{focal}=L_{fea}+L_{at} \]
Global Distillation
利用 GcBlock 在单幅图像中捕捉全局关系信息,并迫使学生探测器从教师那里学习关系。全局Loss为: \[ \begin{aligned} L_{global}=& \lambda\cdot\sum\left(\mathcal{R}(F^T)-\mathcal{R}(F^S)\right)^2 \\ \mathcal{R}(F)=& \begin{aligned}F+W_{v2}(ReLU(LN(W_{v1}\end{aligned} \begin{aligned}(\sum_{j=1}^{N_p}\frac{e^{W_kF_j}}{\sum_{m=1}^{N_p}e^{W_kF_M}}F_j))))\end{aligned} \end{aligned} \]
Overall loss
于是总的Loss为: \[ L=L_{original}+L_{focal}+L_{global} \]
代码实现
1 | |
1 | |
1 | |
Channel-wise Knowledge Distillation for Dense Prediction (ICCV 2021)
不足:
- 以往蒸馏方法都是挖掘空间上的知识
创新点:
- 对通道方向上进行蒸馏
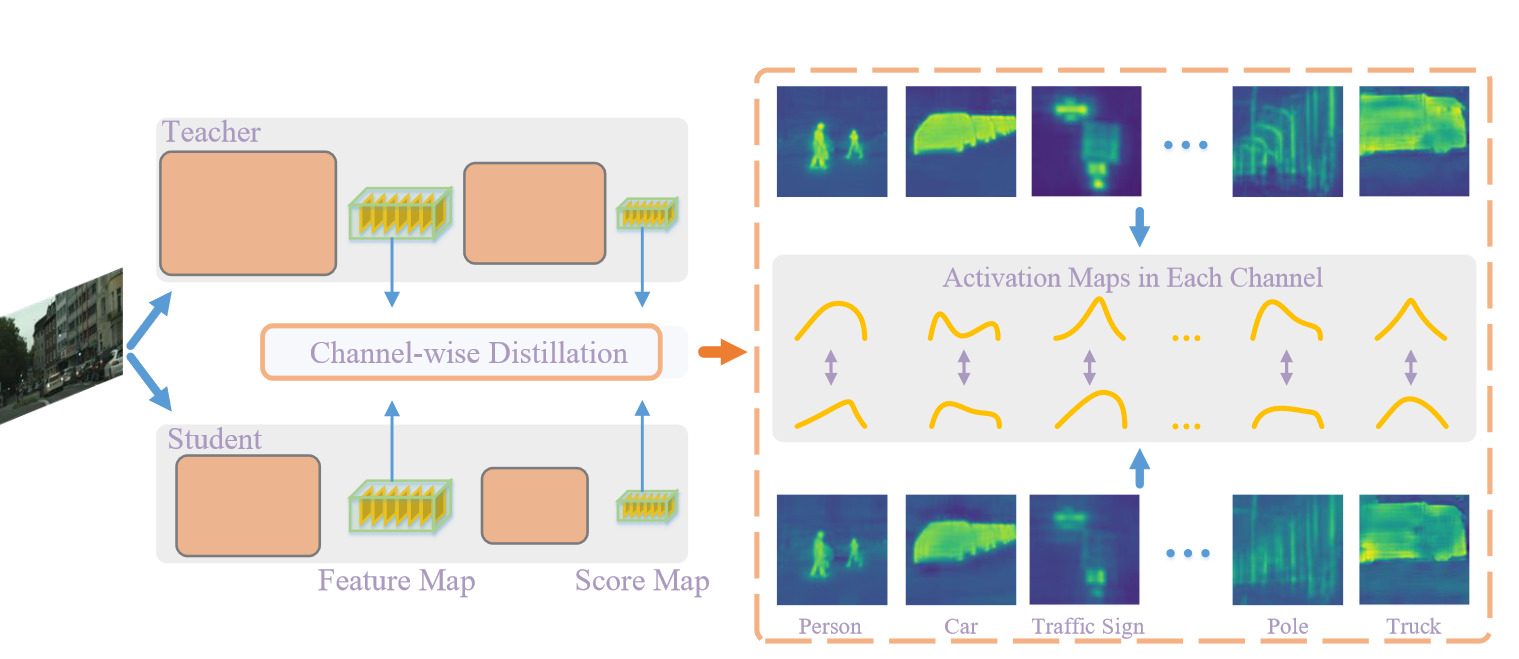
Channel-wise Distillation
整体公式如下所示: \[ \varphi(\phi(y^T),\phi(y^S))=\varphi(\phi(y_c^T),\phi(y_c^S)). \] 其中 \(\phi (\cdot)\) 代表在每个通道内进行softmax操作,\(\varphi(\cdot))\) 用于评估教师网络与学生网络通道分布之间的差异。然后使用KL散度: \[ \varphi\big(y^T,y^S\big)=\frac{\mathcal{T}^2}C\sum_{c=1}^C\sum_{i=1}^{W\cdot H}\phi(y_{c,i}^T)\cdot\log\Big[\frac{\phi(y_{c,i}^T)}{\phi(y_{c,i}^S)}\Big]. \] 这样可以让学生网络倾向于在前景显著性中产生相似的激活分布,而教师网络中对应于背景区域的激活对学习的影响较小。
G-DetKD: Towards General Distillation Framework for Object Detectors via Contrastive and Semantic-guided Feature Imitation(ICCV 2021)
不足:
- 以往的目标检测模型都是划分前景背景来进行蒸馏,但是都是使用在较老没有FPN的目标检测模型上
- 以往的目标检测蒸馏方法都不能使用在异构的目标检测器上
- 不加区分地对所有层级应用相同的掩码,可能会引入无响应特征层级的噪音
创新点:
- 带有语义感知软匹配机制的新型语义引导特征模仿方法(SGFI)
- 对比知识提炼(CKD),以捕捉教师不同特征区域之间的关系所编码的信息。
Semantic-Guided Feature Imitation (SGFI)
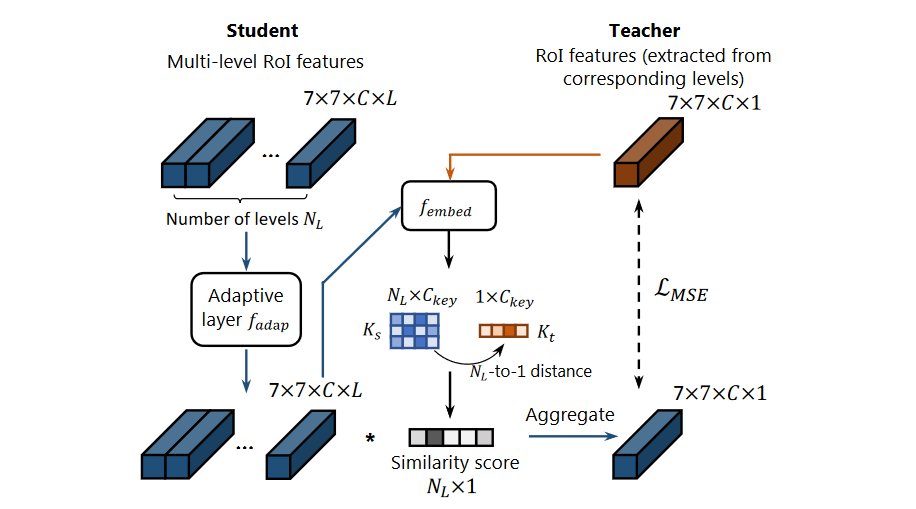
这部分就用一个类似注意力机制的办法来进行蒸馏学习语义信息。首先从启发式指定的金字塔级别中提取教师 \(T_i \in R^{H\times W \times C}\) ,学生特征则是多层中提取的 \(S_i \in R^{L \times H \times W \times C}\),整体如下所示, \[ \begin{gathered} K_{s_{i}}=f_{embed}\left(f_{adap}\left(S_{i}\right)\right),K_{t_{i}}=f_{embed}\left(T_{i}\right) \\ \begin{aligned}\alpha_i=softmax\left(\frac{K_{s_i}K_{t_i}^T}{\tau}\right)\end{aligned} \\ \begin{aligned}S_{agg_i}&=\sum_{l=1}^{L}\alpha_i^l\times f_{adap}\left(S_i^l\right)\end{aligned} \\ L_{feat}=\frac{1}{N}\sum_{i=1}^{N}\left(MSE\left(S_{agg_{i}},T_{i}\right)\right) \end{gathered} \]
Exploiting Region Relationship with Contrastive KD (CKD)
首先给定一个集合B,其中包含N个RoI的bounding box(\(B={bbox}_{1,2,...,N}\)),他们的对应表示是\(\{r^i_s, r^i_t\}_{1,...,N}\) ,是在输出层前的嵌入层提取的。其中对比对(contrastive pair)的定义为:positive为相同box,negative为不同box(\(x_{pos}=\{ r_s^i, r_t^i\}, x_{neg}=\{r^i_s, r^j_t\}(i \ne j)\)),目标是从包含K个负数对的 \(S=\begin{Bmatrix}x_{pos},x_{neg}^1,x_{neg}^2,...,x_{neg}^K\end{Bmatrix}\) 中识别出正数对,以 InfoNCE 损失的形式实现: \[ \begin{aligned}L_{ckd}&=\frac1N\sum_{i=1}^N-\log\frac{g\left(r_s^i,r_t^i\right)}{\sum_{j=0}^Kg\left(r_s^i,r_t^j\right)}\end{aligned} \] g 是估计为正对的概率的批判函数(主要思想就是使用cos相似度来计算概率): \[ g\left(r_{s},r_{t}\right)=\exp\left(\frac{f_{\theta}\left(r_{s}\right)\cdot f_{\theta}\left(r_{t}\right)}{\parallel f_{\theta}\left(r_{s}\right)\parallel\cdot\parallel f_{\theta}\left(r_{t}\right)\parallel}\cdot\frac1\gamma\right) \]
Structural Knowledge Distillation for Object Detection(NeurlPS 2022)
创新点:
- 不使用更复杂的采样机制去提升 l -正则化所带来的弊端
- 通过交叉使得学生能够获取更多的知识
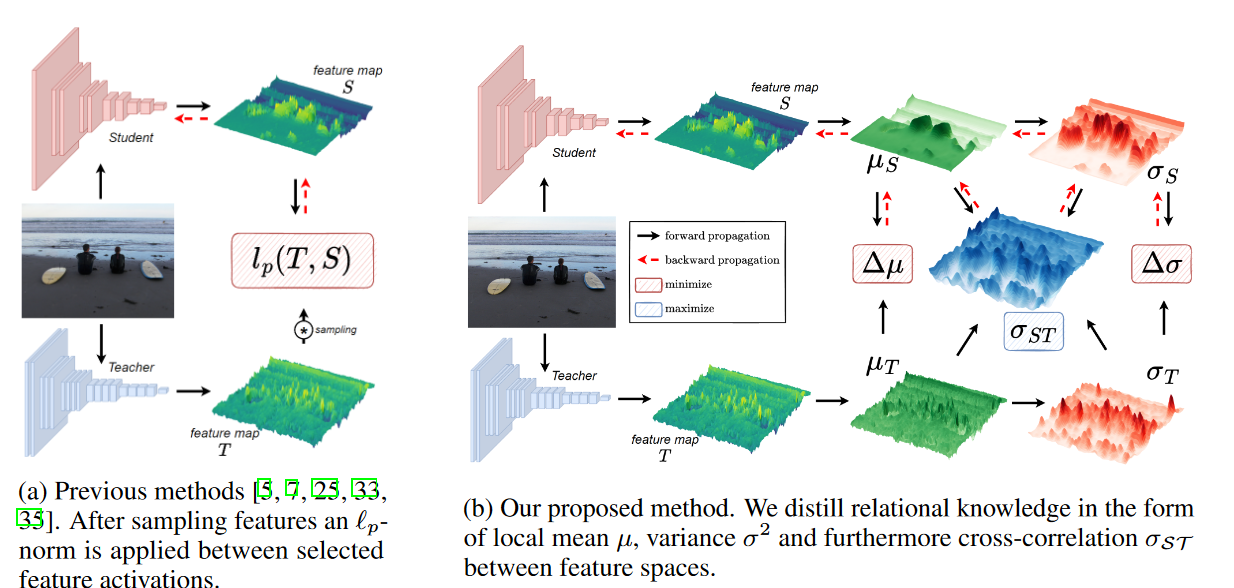
Overview
作者选择neck的输出端分别从教师和学生那里选择中间表征 $^{C,H,W} \(和\)^{C,H,W}$ ,整体蒸馏loss为: \[ \mathcal{L}_{feat}=\sum_{r=1}^R\frac1{N_r}\sum_{h=1}^H\sum_{w=1}^W\sum_{c=1}^C\mathcal{L}_{\varepsilon}\left(\nu\left(\phi\left(\mathcal{S}_{r,h,w,c}\right)\right),\nu\left(\mathcal{T}_{r,h,w,c}\right)\right) \] 其中R是neck的输出数量,\(\nu(\cdot)\) 是归一化方法,作者使用min-max缩放, \(\phi(\cdot)\) 是适应层,为了令T和S的维度相匹配,作者使用一个1x1的卷积。
Measuring Difference
显然,L-norm 函数无法捕捉到特征之间的空间关系。为了捕捉二阶信息,我们需要至少设计两个特征位置,因此我们将问题从point-wise比较修改成patch-wise比较。对于每个patch,我们提取出三个基本属性:均值 \(\mu\),方差 \(\sigma^2\) 和交叉相关性,后者捕捉了 S 和 T 之间的关系。我们使用大小为11 x 11、\(\sigma_F\) =1.5 的高斯加权补丁进行计算。SSIM框架对每种属性进行了比较,由三个部分组成:亮度 \(l\),对比度 \(c\),结构 \(s\),其定义如下: \[ l=\frac{2\mu_{\mathcal{S}}\mu_{\mathcal{T}}+C_1}{\mu_{\mathcal{S}}^2+\mu_{\mathcal{T}}^2+C_1}\quad\mathrm{(3a)}\quad c=\frac{2\sigma_{\mathcal{S}}\sigma_{\mathcal{T}}+C_2}{\sigma_{\mathcal{S}}^2+\sigma_{\mathcal{T}}^2+C_2}\quad\mathrm{(3b)}\quad s=\frac{\sigma_{\mathcal{S}\mathcal{T}}+C_3}{\sigma_{\mathcal{S}}\sigma_{\mathcal{T}}+C_3}\quad\mathrm{(3c)} \] 为了防止不稳定性,\(C_1=(K_1L)^2,C_2=(K_2L)^2,C_3=C_2/2\),其中 L 是特征图的动态范围,K1=0.01,K2=0.03。从公式中可以看到更加重视 l 和 c 的相对变化。于是最后可以将这三个部分结合到一起: \[ \ell_{\mathbf{SSIM}}:\mathcal{L}_{\varepsilon}=(1-\mathrm{SSIM})/2=(1-\left(l^\alpha\cdot c^\beta\cdot s^\gamma\right))/2 \] 其中 \(\alpha,\beta,\gamma\) 的默认值为1.0。由于我们的方法纯粹基于特征,因此与头部或边界框标签的类型无关,我们只需使用加权因子 \(\lambda\) 将 \(\mathcal{L}_{feat}\) 添加到现有的检测目标函数 \(\mathcal{L}_{det}\)(通常为 \(\mathcal{L}_{cls}\) 和 \(\mathcal{L}_{reg}\))中,从而得到以下总体训练目标: \[ \mathcal{L}=\lambda\mathcal{L}_{feat}+\mathcal{L}_{det} \]
PKD: General Distillation Framework for Object Detectors via Pearson Correlation Coefficient(NeurlPS 2022)
不足:
- 教师和学生之间的特征量级差异可能会对学生施加过于严格的限制
- 教师模型中特征量级较大的 FPN 层和通道可能会主导蒸馏损失的梯度,这将压倒 KD 中其他特征的效果,并引入大量噪声
创新点:
- 作者认为,即使师生探测器对是异质的,FPN 特征模仿也能成功地提炼知识。
- 建议用 PCC 来模仿 FPN 特征,以关注关系信息,并放宽学生特征大小的分布限制。
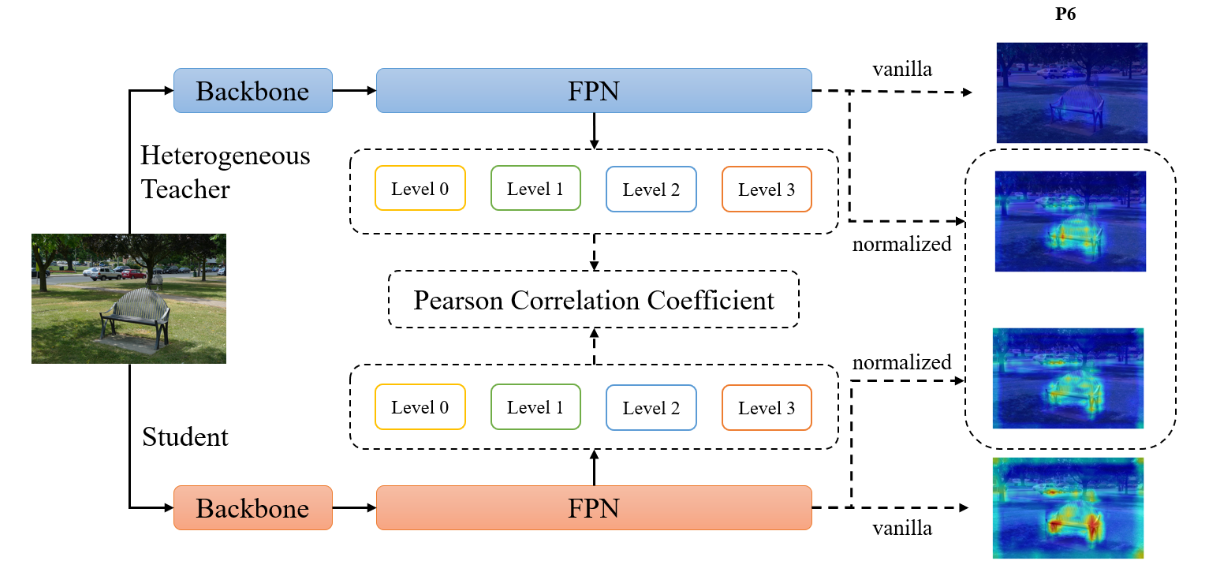
我们建议首先对教师和学生的特征进行归一化处理,使其均值为零,方差为单位,并最小化归一化特征之间的 MSE。此外,我们还希望归一化服从卷积属性--这样,同一特征图中位于不同位置的不同元素就会以相同的方式归一化。让 \(\mathbb{B}\) 成为特征图中所有值的集合,既包括 mini-batch 元素,也包括空间位置。因此,对于大小为 b 的 mini-batch 和大小为 h × w 的特征图,我们使用大小为 \(m=\|\mathbb{B}\|=b\cdot hw\) 的有效迷你批。令 \(s^{(c)} \in \mathbb{R} ^ m\) 作为FPN一个batch输出的第c个通道。之后我们得到来自学生和老师的归一化值 \(\hat{s}_{1...m}\) 和 \(\hat{t}_{1...m}\) 。作者不使用掩码来选择重要特征,而是根据整个特征图进行操作。因此蒸馏loss就是: \[ \mathcal{L}_{FPN}=\frac1{2m}\sum_{i=1}^m(\hat{s}_i-\hat{t}_i)^2 \] 进一步看,最小化上述损失等于最大化学生和教师的预归一化特征之间的皮尔逊系数(PCC)。PCC如下: \[ r(s,\boldsymbol{t})=\frac{\sum_{i=1}^m(s_i-\mu_s)(t_i-\mu_t)}{\sqrt{\sum_{i=1}^m(s_i-\mu_s)^2}\sqrt{\sum_{i=1}^m(t_i-\mu_t)^2}}. \] 因为 \(\hat{s},\hat{t}\sim\mathcal{N}(0,1)\),我们可以得到 \(\frac1{m-1}\sum_i\hat{s}_i^2=1,\frac1{m-1}\sum_i\hat{t}_i^2=1\)。那么我们可以将公式重拟为: \[ \begin{aligned} \mathcal{L}_{FPN}& =\frac1{2m}\left((2m-2)-2\sum_{i=1}^m\hat{s}_i\hat{t}_i\right) \\ &=\frac{2m-2}{2m}(1-r(s,\boldsymbol{t}))\approx1-r(s,\boldsymbol{t}) \end{aligned} \] PCC范围是[-1, 1],如果PCC为1就代表二者具有线性关系在同一条支线上,s增加t也增加。
总之,PCC 专注于来自教师的关系信息,放松了对学生特征大小的分布限制。此外,它还消除了占主导地位的 FPN 阶段和通道的负面影响,从而获得更好的性能。因此,归一化机制弥合了学生和教师激活模式之间的差距(见图 2)。因此,使用 PCC 进行特征模仿适用于异质检测器对。最后模型训练的Loss为:
\[ \mathcal{L}=\mathcal{L}_{GT}+\alpha\mathcal{L}_{FPN}, \]
Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection(ICCV 2023)
不足:
- 密集目标检测面临严重的前景背景不平衡问题。因此密集目标检测一般最后使用Sigmoid,而分类蒸馏任务一般选择的是softmax。Softmax对分类分数进行了归一化,忽略了各个类别的绝对分数并且消除了样本间的差异特征。此外,在蒸馏中,每个类别的分类分数与类间依赖性联合优化,而在密集对象检测中,它们在没有此类依赖性的情况下单独优化。这些差异导致了跨任务协议不一致问题,如图1(b)所示:当Softmax后教师分数与学生分数相等时,分类蒸馏损失为0,表明学生分数已经达到最优溶液中的蒸馏损失。而实际上学生的Logit差别很大。
- 定位是目标检测的一大问题,尽管LD(上面那篇TPAMI)已经证明了定位蒸馏损失是有效的,但是他需要离散位置概率预测头,这是一大限制。
创新点:
- 作者提出了两个新颖的蒸馏损失,二元分类蒸馏损失和IoU-based定位蒸馏损失,为分类和定位量身定制。
- 在分类中,作者将跨任务不平衡协议转换成平衡。具体来说,我们将密集目标检测器中的分类logit图视作K个二元分类图。之后,我们使用Sigmoid去获得分数以及使用二元交叉熵损失去蒸馏每个二元分类图,能够有效解决跨任务的不平衡问题。
- 对于定位,我们将依赖特殊结构的定位蒸馏损失转换为无特殊结构的定位蒸馏损失。具体来说,我们直接计算教师和学生生成的预测边框之间的IoU,并使用IoU损失来最小化IoU值与1之间的差异。
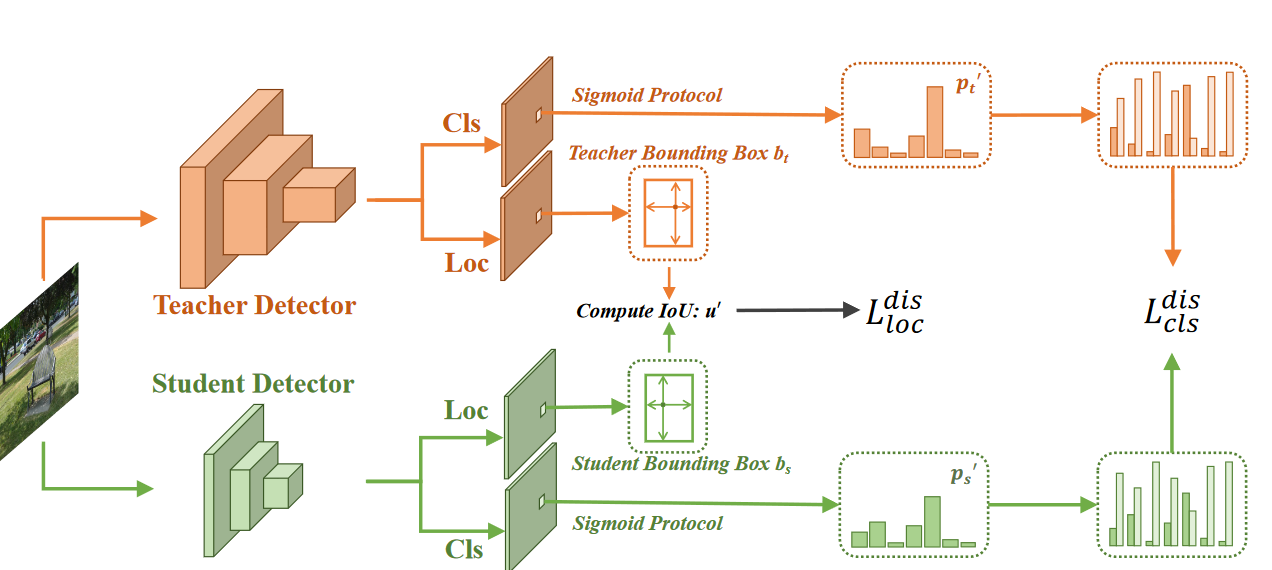
Binary Classification Distillation Loss
为了弥补跨任务协议的不一致,我们提出了一个简单但有效的解决方案。具体来说,我们在蒸馏过程中将分类 Logit 图视为多个二元分类图。为了解决这个问题,我们提计算 \(p^{t^{\prime}}=Prot_{Sig}(l^t)\mathrm{~and~}p^s{'}=Prot_{Sig}(l^s)\) ,获得二元分类分数 \({p^t}^\prime\) 和 \({p^s}^\prime\) ,他们大小为 n x K,n为anchor数量,K为类别数量。之后分类损失就可以通过这个二元分类分数进行计算分类损失: \[ \begin{aligned} &\mathcal{L}_{BCE}({p_{i,j}^{s}},{p_{i,j}^{t}}^{\prime})= -\left((1-{p_{i,j}^t}^{\prime})\cdot log(1-{p_{i,j}^s}^{\prime})+{p_{i,j}^t}^{\prime}\cdot log({p_{i,j}^s}^{\prime})\right) \\ &\begin{aligned}\mathcal{L}_{cls}^{dis}(x)=\sum_{i=1}^n\sum_{i=1}^K\mathcal{L}_{BCE}(p_{i,j}^s,p_{i,j}^t,^{\prime})\end{aligned} \end{aligned} \] 此外,我们提出了一个损失权重来使模型更加专注于重要的样本。具体来说我们先计算重要性权重: \[ w=\left|p^{t'}-p^{s'}\right| \] 因此分类蒸馏损失最终为: \[ \mathcal{L}_{cls}^{d\boldsymbol{i}s}(x)=\sum_{i=1}^n\sum_{j=1}^Kw_{i,j} \cdot \mathcal{L}_{BCE}(p_{i,j}^s,{p_{i,j}^t}^{\prime}) \]
IoU-based Localization Distillation Loss
我们计算 \(b^t_i\) 和 \(b^s_i\) 之间的IoU并记为 \(u^\prime_i\) ,此外也使用了上述的权重来侧重于更重要的样本,最后可以得到如下loss: \[ \mathcal{L}_{loc}^{dis}(x)=\sum_{i=1}^nmax(w_{.,j})\cdot(1-u_{i}^{\prime}) \]
Total Distillation Loss
最后合并两个损失为: \[ \mathcal{L}_{total}^{dis}(x)=\alpha_1\cdot\mathcal{L}_{cls}^{dis}(x)+\alpha_2\cdot\mathcal{L}_{loc}^{dis}(x) \]
UniKD: Universal Knowledge Distillation for Mimicking Homogeneous or Heterogeneous Object Detectors(ICCV 2023)
不足:
- 如何在不同类型的教师-学生对之间进行知识传递是一个很实用且具有挑战的一个标题
创新点:
- 提出了一个query-based蒸馏范式,叫做Universal Knowledge Distillation(UniKD)
- 在UniKD中,我们提出了Adaptive Knowledge Extractor(AKE)模块,是一个具有可变性交叉注意力的额外transformer解码器头。
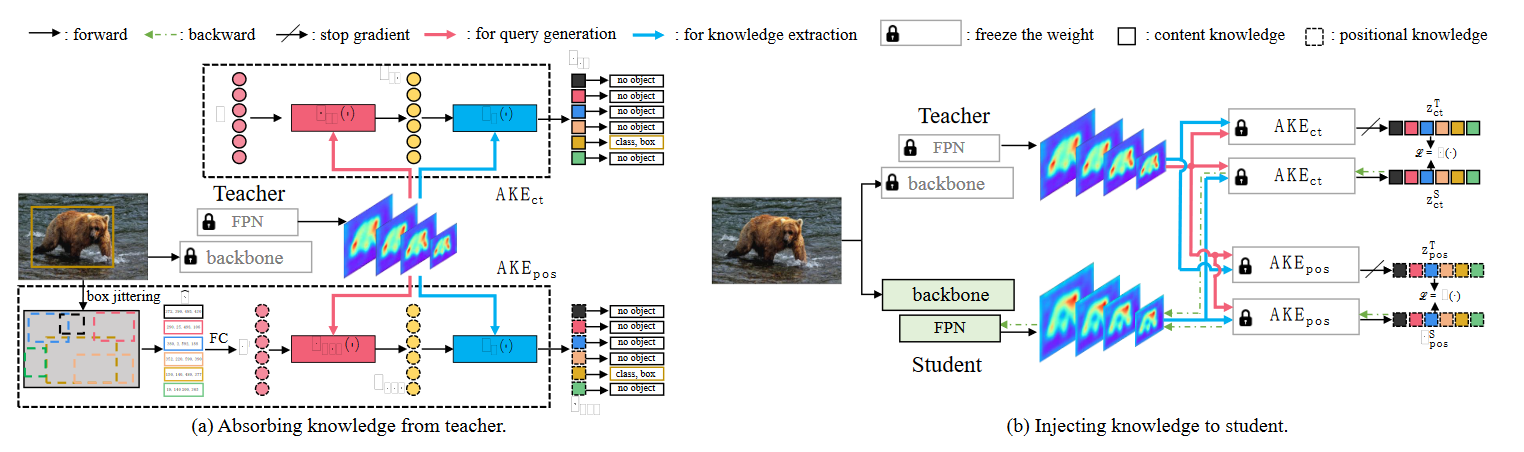
Universal Knowledge Distillation
UniKD可以被视为一个two-stage学习范式:
- 从教师吸取知识
- 注射知识进学生
Architecture of AKE module
AKE包含两个组件:query提取器(\(f_{ct} \ or\ f_{pos}\))和detection-relevant知识提取器(\(f_e\))。UniKD最终蒸馏损失是减少学生和教师之间的知识embedding \(z\),而不是直接的特征图。有两种类型的AKE模块,\(AKE_{ct}\) 用于提取content knowledge embedding \(z_{ct}\),\(AKE_{pos}\) 用于提取positional knowledge embedding \(z_{pos}\)。他们使用的相同的结构,但是输入的query是不一样的,并且参数不共享。AKE可以用公式表示为: \[ \left\{\begin{array}{l} \mathrm{AKE}_{\mathrm{ct}}: \underset{N \times C}{\mathrm{E}} \stackrel{f_{c t}(\cdot)}{\longrightarrow} \underset{N \times C}{q_{c t}} \stackrel{f_{e}(\cdot)}{\longrightarrow} \underset{N \times C}{z_{c t}} \\ \mathrm{AKE}_{\mathrm{pos}}: \underset{N \times 4}{ \hat{B}}\stackrel{FC}{\longrightarrow} \underset{N \times C}{\mathrm{E}^{\prime}} \stackrel{f_{p o s}(\cdot)}{\longrightarrow} \underset{N \times C}{q_{p o s}} \stackrel{f_{e}(\cdot)}{\longrightarrow} \underset{N \times C}{z_{p o s}} \end{array}\right. \] 其中N代表query数量,C代表通道维度
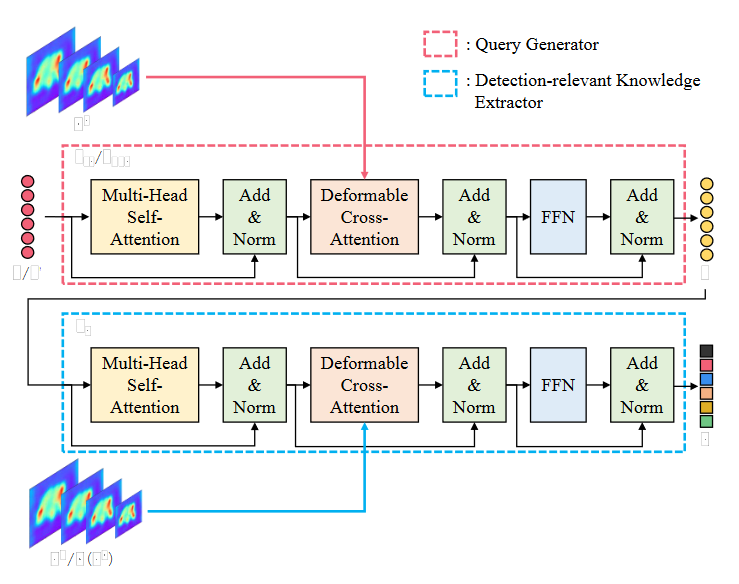
Query Generator 我们先生成两种类型的输入embedding,\(E\) 为了content knowledge提取和 \(E^\prime\) 为了positional knowledge提取。\(E \in \mathbb{R}^{N\times C}\) 代表初始化的可学习的解码器输入。 \(E^\prime \in \mathbb{R}^{N\times C}\) 代表通过 \(\hat{B} \in \mathbb{R}^{N\times C}\) 获得的潜在embedding,\(\hat{B}\) 代表带注释的ground-truth \(B\) 周围的抖动框和随机采样的背景框。具体来说,给定一个带注释的 \(B \in \mathbb{R}^{N^\prime\times C}\) ,其中 \(N^\prime\) 代表box数量。我们首先对每个ground-truth box采样一个抖动框。之后在ground-truth周围随机采样一个batch的背景框,并保留与ground-truth最大IoU并且低于 \(\beta\) 的背景框。重复此过程,直到背景框的数量满足 \(N-N^\prime\) 。\(B^\prime\) 的生成可以如下表示: \[ \hat{B}_i=\begin{cases}\text{jitter}(B_i)\text{s.t. IoU}_{(\hat{B}_i,B_i)}>\alpha,&i\in\{1,\ldots,N'\}\\\text{Rand s.t. max}\{\text{IoU}_{(\hat{B}_i,B)}\}<\beta,&i\in\{N'+1,\ldots,N\}\end{cases} \] 根据经验,\(\alpha\ and \ \beta\) 杯分别设置为0.6和0.4。之后我们采用一个全连接的方式来转换 \(\hat{B}\) 到 \(E^\prime\) 。
随着 \(E \ and \ E^\prime\) 作为输入,两种query就被生成:content queries \(q_{ct}\) 和 positional queries \(q_{pos}\) 。我们将query生成过程表示为: \[ \begin{aligned}q_{ct}&=f_{ct}(E,F^T)\\q_{pos}&=f_{pos}(E^{\prime},F^T)\end{aligned} \] 其中 \(f_{ct} \ and \ f_{pos}\) 都由一个tranformer的decoder层组成。在\(F^T\) 上使用Deformable cross-attention为了帮助生成的query是动态的并且依赖于输入图像。
Detection-relevant Knowledge Extractor. 得到了query \(q_{ct}\) 和 \(q_{pos}\) ,我们之后使用他们作为probes,通过与多尺度特征 \(F^*\) 的deformable cross-attention来提取检测相关知识。模块中这部分称为detction-relevant knowledge extractor。将这一个操作由如下表示: \[ \begin{aligned}z_{ct}&=f_e(q_{ct},F^*)\\z_{pos}&=f_e(q_{pos},F^*)\end{aligned} \] 其中 \(F^*\) 可以是 \(F^T\mathrm{~or~}\phi(F^S)\) 。两个\(f_e\) 都是由decoder层堆栈组成的,参数不共享。AKE的完整参数量仅有1.56M。
Absorbing knowledge from teacher
在第一个步骤中,我们只是用教师来预训练AKE模块。这个预训练步骤促进了知识embedding \(z\) 去学习什么知识对于检测一个实例是重要的,这一个步骤我们称为从教师吸取知识。
对于content知识,我们首先令其与输入\(F^T\)获得content知识embedding \(z_{ct}^T\) 。通过附属的FFN,将其预测出N个固定长度的预测集。受DETR启发,我们对\(z_{ct}\)和ground-truth进行了一个双向匹配。匹配后,输出emedding \(z_{ct}^T\) 被分成positive和negative \(z_{ct}\) 。\(\sigma^{ct}(i)\) 杯定义为第i个query的目标index。具体来说,如果第 i 个query属于positive,\(B_{\sigma^{ct}(i)}\) 是他的ground-truth,\(y_{\sigma^{ct}(i)}\) 是他的标签。剩下的就没有目标box以及 \(y_{\sigma^{ct}(i)}\) 代表背景标签。对于positional knowledge,我们首先获得embedding \(z_{pos}^T\) 。之后遵循相同的方式进行划分。最后第一个步骤的loss为: \[ \begin{aligned} \mathcal{L}_{*}^{T}=& \frac1{N'}\sum_{i\in\mathcal{P}^*}\mathcal{L}_{box}(\text{FFN}(z_{*_i}^T),B_{\sigma^*(i)})+ \\ &\frac1N\sum_{i\in\mathcal{P}^*\cup\mathcal{N}^*}\mathcal{L}_{cls}(\mathrm{FFN}(z_{*_i}^T),y_{\sigma^*(i)}), \end{aligned} \] 其中 * 可以是ct或者pos。
Injecting knowledge to student
在第二个步骤中,我们冻结AKE中的参数。注意AKE在教师和学生之间共享相同的query generator 作为输入。最后loss为: \[ \begin{aligned} \mathcal{L}_{kd}& =\lambda_1\mathcal{D}(\mathrm{AKE}_{\mathrm{ct}}(F^T,\phi(F^S)),\mathrm{AKE}_{\mathrm{ct}}(F^T,F^T))+ \\ &\lambda_2\mathcal{D}(\mathrm{AKE}_{\mathrm{pos}}(F^T,\phi(F^S)),\mathrm{AKE}_{\mathrm{pos}}(F^T,F^T)) \\ &=\lambda_1\mathcal{D}(z_{ct}^S,z_{ct}^T)+\lambda_2\mathcal{D}(z_{pos}^S,z_{pos}^T), \end{aligned} \] 其中loss方法 \(\mathcal{D}(\cdot)\) 具体为: \[ \begin{aligned} \mathcal{D}(z^{S},z^{T})=& \begin{aligned}\frac{1}{N'}\sum_{i\in\mathcal{P}}\text{MSE(z i S,z i T)+}\end{aligned} \\ &\begin{aligned}\frac{1}{N-N'}\sum_{i\in\mathcal{N}}\mathrm{MSE(z_i^S,z_i^T)}.\end{aligned} \end{aligned} \]
Multi-level Logit Distillation (CVPR 2023)
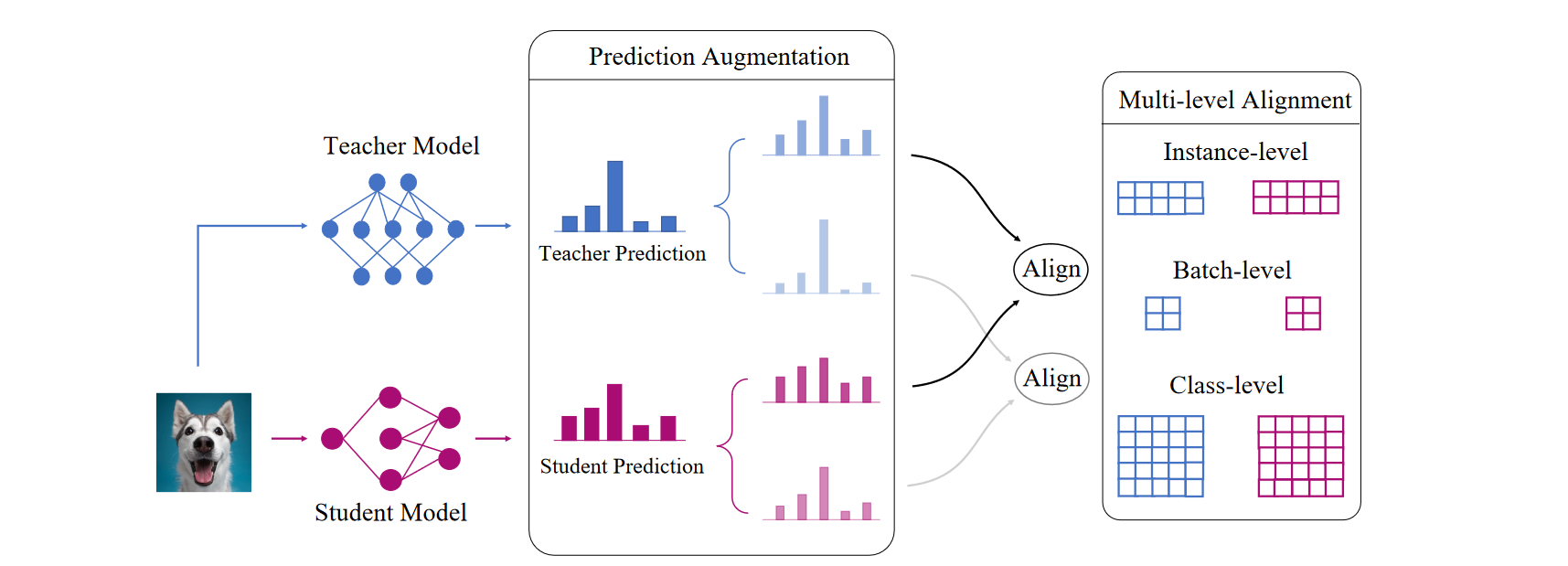
多级Logit蒸馏使用的不是单个数据的输出,而是整个Batch的输出。我们将Logit输出表示为 \(z \in \mathbb{R}^{V \times C}\) ,其中B是batch size,C是类别。我们的方法又两个核心部分:(1)预测增强(2)多层对齐
Prediction Augmentation
我们通过模型校准进行预测增强。我们采取温度定标,一种广泛采用的定标方法。 \[ p_{i,j,k}=\frac{e^{z_{i,j}/T_k}}{\sum_{c=1}^Ce^{z_{i,c}/T_k}}, \] 使用多个温度便可以获得多个预测输出。
Multi-level Alignment
通过增加预测,我们提出将教师输出和相应的学生输出(根据温度)一一对应。不同于传统的基于KL散度的logit对齐,我们提出了一种新的多级对齐方法,包括1 )实例级对齐,2 )批级对齐和3 )类级对齐。
Instance-level Alignment 我们继承了原始KD机制中进行实例级的对齐。具体来说,我们一对一最小化教师和学生之间增强的预测的KL散度: \[ \begin{aligned} L_{ins}& =\sum_{i=1}^N\sum_{k=1}^KKL(p_{i,k}^{tea}||p_{i,k}^{stu}) \\ &=\sum_{i=1}^N\sum_{k=1}^K\sum_{j=1}^Cp_{i,j,k}^{tea}log(\frac{p_{i,j,k}^{tea}}{p_{i,j,k}^{stu}}), \end{aligned} \] 和原始KD的核心不同就是我们的方法具有多个预测值进行学习。
Batch-level Alignment 我们建议通过输入相关性(两个输入之间的关系)进行批量级对齐,而不是仅在实例级别对齐预测,这是通过以前的工作中的特征进行建模的。在我们的方法中,我们采用逻辑预测来量化它。我们计算模型预测的Gram矩阵: \[ G^k=p_kp_k^T,G_{ab}^k=\sum_{j=1}^Cp_{a,j,k}\cdot p_{b,j,k} \] 其中 \(G^k\) 是一个BxB的矩阵,以及 \(p_k\) 代表通过 \(T_k\) 获得的预测。我们可以获得 \(G_{ab}^k\) 对第a个和第b个输入分类到同一块的概率建模,这表明了它们之间的关系。之后根据不同的 \(T_k\),分别通过学生和教师的预测计算输入相关矩阵 \(G_k\)。我们的目标是减轻他们的差异,因此相应的损失可以是: \[ L_{batch}=\frac1B\sum_{k=1}^K||G_{tea}^k-G_{stu}^k||_2^2, \] Class-level Alignment 我们指出模型预测可以描述类别之间的关系,例如如果一个类与真实类别很相似,那么模型很容易在他们之间表现出不情愿,形成预测的两个高峰。这种类别相关性可以通过对一个batch的数据预测来建模,如下所示: \[ M^k=p_k^Tp_k,M_{ab}^k=\sum_{i=1}^Np_{i,a,k}\cdot p_{i,b,k} \] 其中 \(M_k\) 是一个CxC的矩阵, \(M_{ab}\) 代表一个batch中的输入同时被分类到第a类和第b类的概率,这能计算出两个类之间的关系。量化类别相关性后,我们可以通过以下损失强制学生模型从教师模型中吸收这部分知识: \[ L_{class}=\frac1C\sum_{k=1}^K||M_{tea}^k-M_{stu}^k||_2^2 \] Multi-level Alignment 最后总的loss为: \[ L_{total}=L_{ins}+L_{batch}+L_{class}. \]
ScaleKD: Distilling Scale-Aware Knowledge in Small Object Detector(CVPR 2023)
不足:
- Small Object Detector(SOD )通常受到噪声特征表示的影响。由于小物体的性质,它们通常占据整个图像中的一小部分区域,因此这些小物体的特征表示可能会被背景和其他尺寸相对较大的实例污染。
- 物体检测器对小物体上的噪声边界框的容忍度较低。教师模型不可避免地会做出错误的预测。教师边界框上的小扰动可能会极大地损害学生检测器上的 SOD 性能。
创新点:
- 尺度解耦的特征蒸馏模块,将教师的特征表示分解为多尺度嵌入,从而能够在小物体上对学生模型进行显式特征模仿。
- 跨尺度助手,用于细化嘈杂且无信息的边界框预测学生模型,这可能会误导学生模型并损害知识蒸馏的功效。
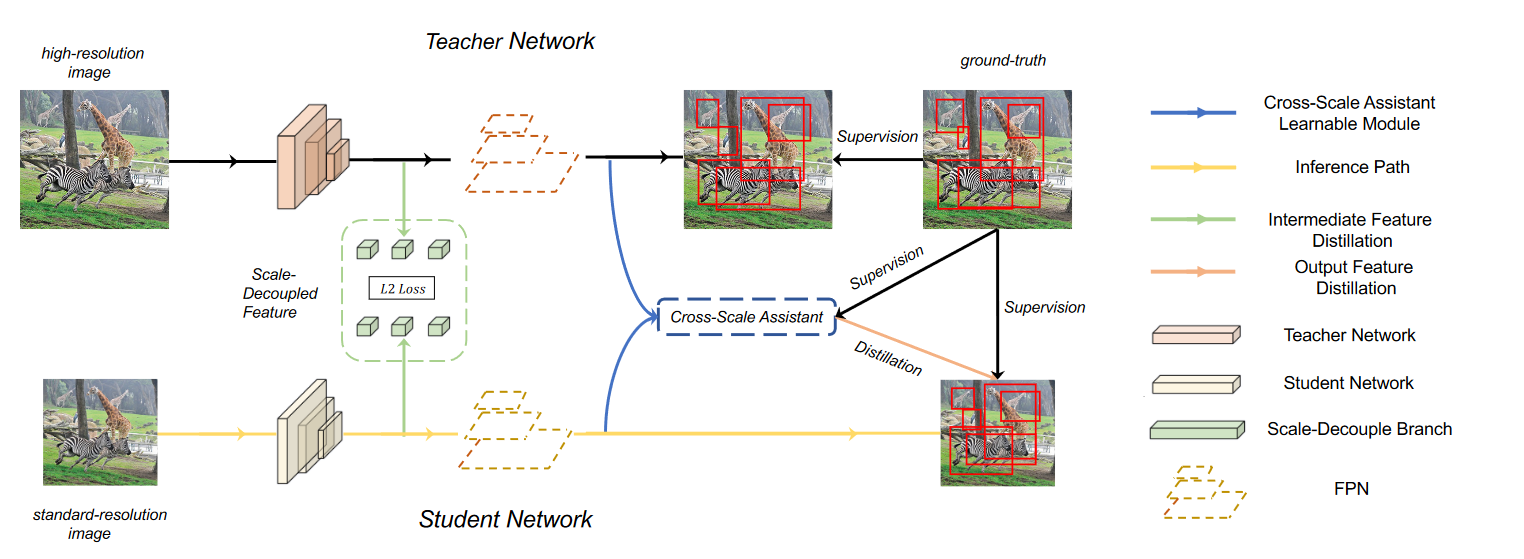
Scale-Decoupled Feature Distillation
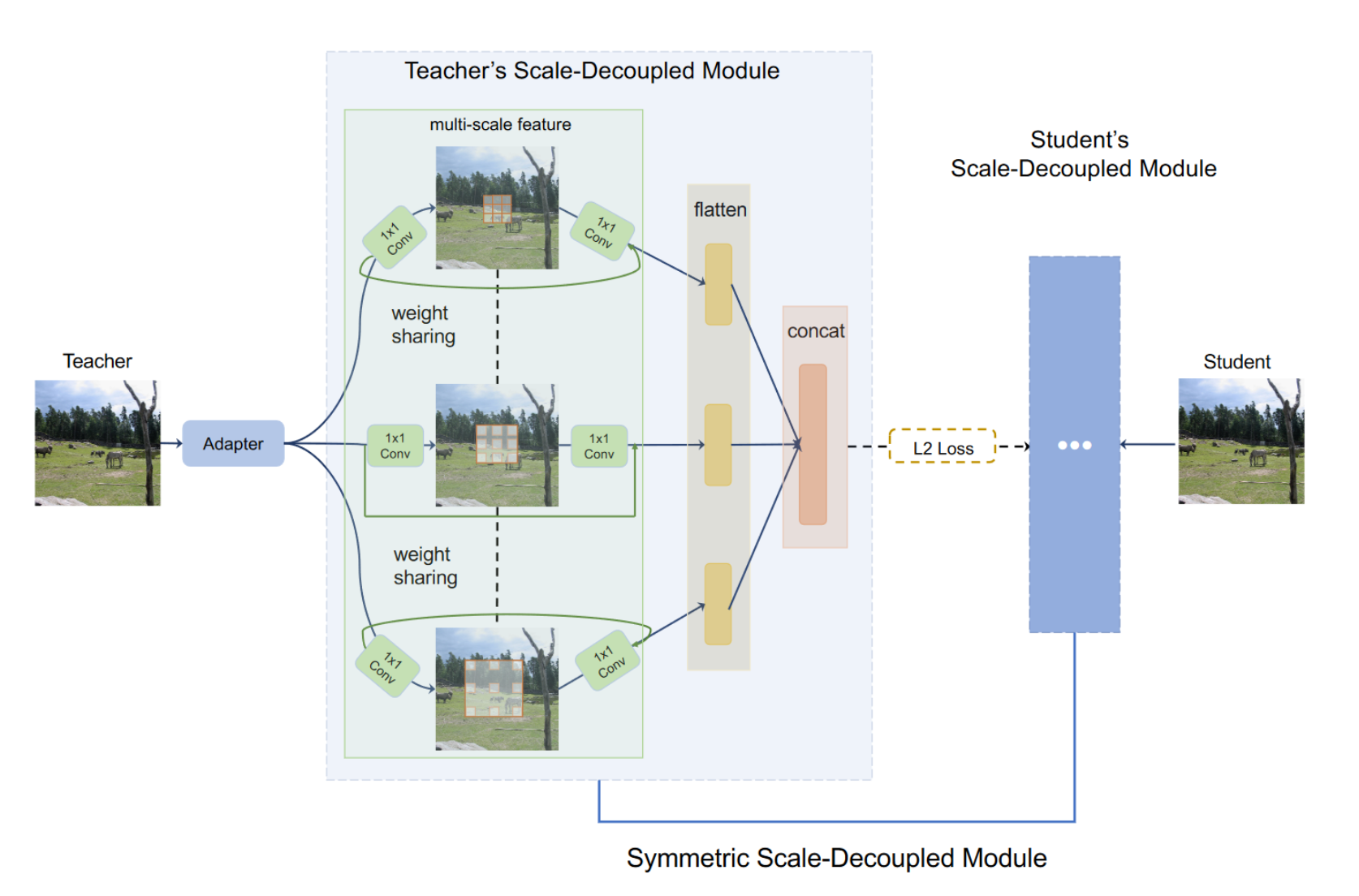
我们的目标是分解教师的特征表达为多个部分,其中每个部分仅解决相似的目标大小。据推测,这样的操作可以迫使学生检测器不仅理解整个图像的全局知识,而且还理解特定尺度的知识。
为了充分利用多尺度的图像特征,我们采用了一个多分支结构,其中每一个分支使用了不同扩张率的卷积层。我们使用ResNet中的残差模块,其中包含三个卷积层(1x1, 3x3, 1x1)以及一个跳跃连接。对于3x3的卷积层,我们在三个分支中使用不同的扩张率(1, 2, 3)。
如果我们对数据间每个分支间进行匹配计算loss,会占用大量内存。因此,我们从神经架构搜索中的权重共享网络中汲取灵感,并采用权重共享尺度解耦特征。这是基于以下事实:所有三个分支都具有相同的运算符。在实践中,我们只保存三个分支的一组权重,大大降低了训练内存成本。
同时我们注意到使用三个独立loss来匹配三个平行的分支会造成大量成本来在超参数调整上。最后,对于每个分支,我们使用一个flattened层,最后将三个拉直的向量concat起来。最后使用L2作为loss。
Cross-Scale Assistant
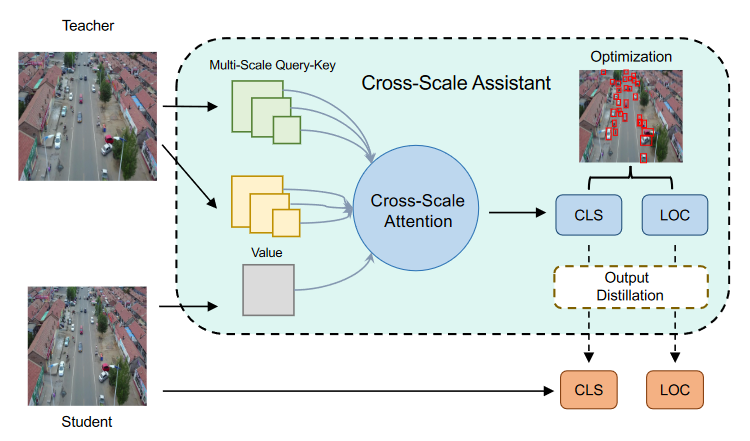
我们通过cross-attention模块来搭建 Cross-Scala Assistant。在交叉注意力中,在教室知识范围内生成一系列的key和query来计算KQ注意力,然后与学生模型的输出张量进行映射,以获得每个对应query的特征中的注意区域。这个过程在每个学生金字塔尺度上执行,以检索基于信息区域的特征。当图像中出现大物体时,交叉注意力会将注意力转向这些大物体,而忽略小物体。为此,与普通的交叉注意力相比,我们开发了一个多尺度交叉注意力层。我们将melti-scale cross-attention(MSC) 公式化: \[ \begin{aligned} Q_i=F^SW_i^Q \\ {I} {_i}=MSC(F^{T},r_{i})W_{i}^{K},V_{i}=MSC(F^{T},r_{i})W_{i}^{V}, \\ V_i=V_i+P(V_i) \end{aligned} \] 其中 \(MSC(\cdot, r_i)\) 是在第i个头中聚合的 MLP 层,下采样率为 \(r_i\),\(P(\cdot)\) 是用于投影的卷积层。与标准交叉注意力相比,保留了更多有利于SOD的细粒度和低级细节。最后,我们通过以下方式计算注意力张量: \[ h_i=Softmax(\frac{Q_iK_i^T}{\sqrt{d_h}}V_i) \] 其中 \(d_h\) 是维度。总的loss为: \[ L_{total}=\alpha L_{feat}+\beta L_{cls}+\gamma L_{bbox}+L_{det} \]
Decoupled Knowledge Distillation(CVPR 2022)
不足:
- 传统KD的loss包含两个部分,目标类别蒸馏(TCKD)和非目标类别蒸馏(NCKD),传统KD抑制了NCKD的有效性,并且限制了两个部分之间平衡的灵活性
创新点:
- 为了解决这些问题,我们提出了一种灵活高效的 Logit 蒸馏方法,称为Decoupled Knowledge Distillation(DKD)。 DKD 通过将 NCKD 损失与与教师置信度负相关的系数解耦,将其替换为常数值,从而提高了对预测良好的样本的蒸馏效率。同时,NCKD和TCKD也是解耦的,可以通过调整各部分的权重来单独考虑它们的重要性。
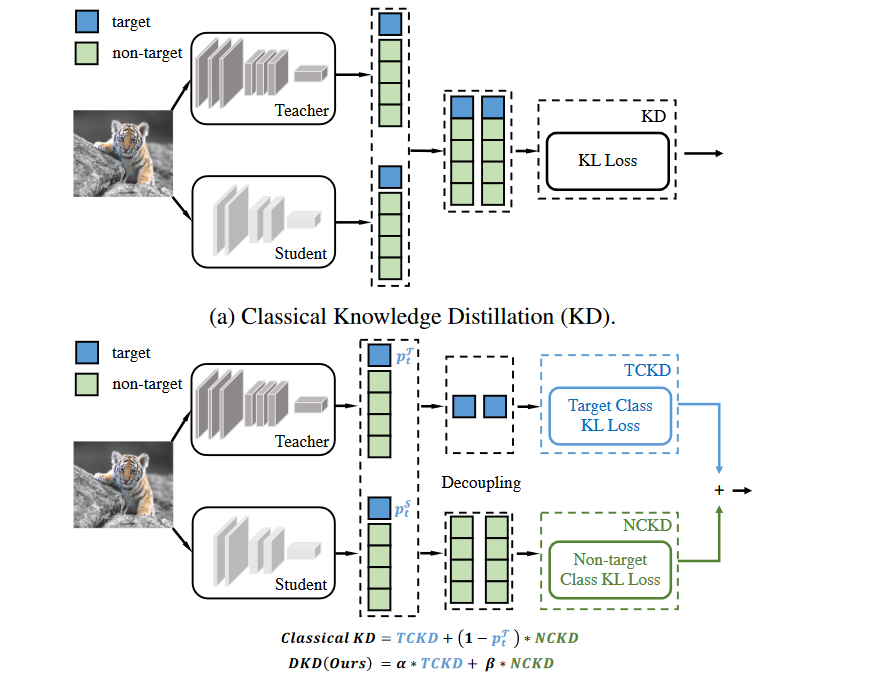
Reformulating KD
Notations 为了分离与目标类别相关和不相关的预测,我们定义了如下符号。 \(b = [p_t, p_{\textbackslash t}] \in \mathbb{B}^{1 \times 2}\) 代表目标类别 \(p_t\) 和非类别 \(p_{\textbackslash t}\) 的二元概率,可以通过如下计算得到: \[ p_t=\frac{\exp(z_t)}{\sum_{j=1}^C\exp(z_j)},p_{\backslash t}=\frac{\sum_{k=1,k\neq t}^C\exp(z_k)}{\sum_{j=1}^C\exp(z_j)}. \] 同时,我们声明 \(:\hat{\mathbf{p}}=[\hat{p}_{1},...,\hat{p}_{t-1},\hat{p}_{t+1},...,\hat{p}_{C}] \in \mathbb{R}^{1 \times (C-1)}\) 去独立构建非目标类别中的概率。每个元素被如下计算: \[ \hat{p_i}=\frac{\exp(z_i)}{\sum_{j=1,j\neq t}^C\exp(z_j)} \] Reformulation 传统使用KL-Divergence作为loss的KD可以被写为: \[ \begin{aligned} \text{KD}& =\mathrm{KL}(\mathbf{p}^{\mathcal{T}}||\mathbf{p}^{\mathcal{S}}) \\ &=p_t^\mathcal{T}\log(\frac{p_t^\mathcal{T}}{p_t^\mathcal{S}})+\sum_{i=1,i\neq t}^Cp_i^\mathcal{T}\log(\frac{p_i^\mathcal{T}}{p_i^\mathcal{S}}). \end{aligned} \] 根据前面的等式,我们可以得到 \(\hat{p_i}=p_i / p_{\backslash t}\) ,所以我们可以重写上面的公式: \[ \begin{aligned} \text{KD}& =p_t^{\mathcal{T}}\log(\frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}})+p_{\backslash t}^{\mathcal{T}}\sum_{i=1,i\neq t}^{C}\hat{p}_i^{\mathcal{T}}(\log(\frac{\hat{p}_i^{\mathcal{T}}}{\hat{p}_i^{\mathcal{S}}})+\log(\frac{p_{\setminus t}^{\mathcal{T}}}{p_{\setminus t}^{\mathcal{S}}})) \\ &=\underbrace{p_t^{\mathcal{T}}\log(\frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}})+p_{\backslash t}^{\mathcal{T}}\log(\frac{p_t^{\mathcal{T}}}{p_t^{\mathcal{S}}})}_{\mathrm{KL}(\mathbf{b}^{\mathcal{T}}||\mathbf{b}^{\mathcal{S}})}+\underbrace{p_{\backslash t}^{\mathcal{T}}\sum_{i=1,i\neq t}^{C}\hat{p}_i^{\mathcal{T}}\log(\frac{\hat{p}_i^{\mathcal{T}}}{\hat{p}_i^{\mathcal{S}}})}_{\mathrm{KL}(\hat{\mathbf{p}}^{\mathcal{T}}||\hat{\mathbf{p}}^{\mathcal{S}})}. \end{aligned} \] 之后最后的等式可以写为: \[ \mathrm{KD}=\mathrm{KL}(\mathbf{b}^\mathcal{T}||\mathbf{b}^\mathcal{S})+(1-p_t^\mathcal{T})\mathrm{KL}(\hat{\mathbf{p}}^\mathcal{T}||\hat{\mathbf{p}}^\mathcal{S}) \] 这样KD的loss就被重新分为了两个部分的加权和,\(\mathrm{KL}(\mathbf{b}^\mathcal{T}||\mathbf{b}^\mathcal{S})\) 代表老师和学生之间的目标类别二元概率的相似度。同时另外一部分代表学生和老师非目标类别概率的相似度。最后还可以重写为: \[ \mathrm{KD}=\mathrm{TCKD}+(1-p_t^{\mathcal{T}})\text{NCKD}. \] 显而易见,NCKD的权重由 \(p_t^\mathcal{T}\) 耦合。
Effects of TCKD and NCKD
验证了 TCKD 的有效性并揭示了 NCKD 的抑制作用。具体来说,TCKD 传递有关训练样本“难度”的知识。 TCKD 在更具挑战性的训练数据上可以获得更显着的改进。 NCKD 在非目标类之间传递知识,在权重$ (1 − p_t^ ) $相对较小的情况下,知识会被抑制。
Decoupled Knowledge Distillation
受益于我们对 KD 的重新表述,我们提出了一种新颖的逻辑蒸馏方法,称为解耦知识蒸馏(DKD)来解决上述问题。我们提出的 DKD 在解耦公式中独立考虑 TCKD 和 NCKD。具体来说,我们引入两个超参数α和β,分别作为TCKD和NCKD的权重。 DKD的损失函数可以写成如下: \[ \mathrm{DKD}=\alpha\text{TCKD}+\beta\text{NCKD}. \]
Dual Relation Knowledge Distillation for Object Detection(IJCAI2023)
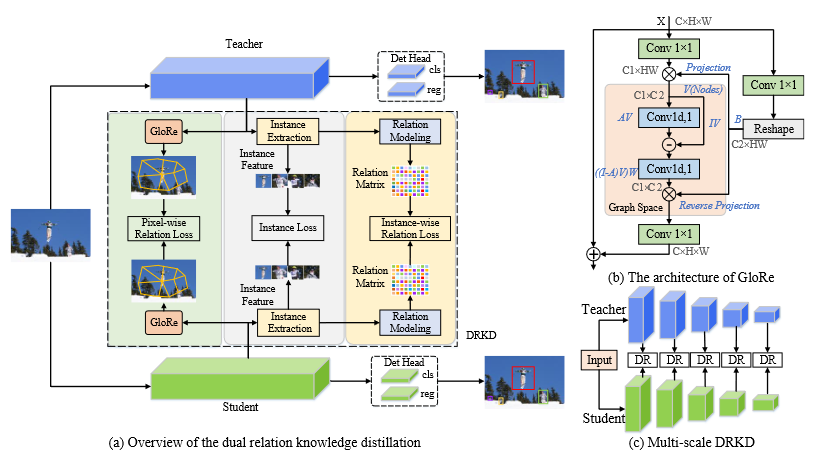
Pixel-wise Relation Distillation
像素级关系蒸馏帮助学生检测器学习前景和背景特征之间的关系,解决特征不平衡问题。采用名为 GloRe 的图卷积模块来捕获全局像素关系。它可以比注意力机制更有效地捕获全局上下文,达到更好的蒸馏效果。
具体来说,我们分别从教师和学生的主干中提取多尺度特征,并将它们输入到不同的 GloRe 模块以捕获全局像素关系。蒸馏公式如下所示: \[ L_{PR}=\dfrac{1}{k}\sum_{i=1}^{k}\|\phi(t_i)-f(\phi(s_i))\|_2 \] 其中 \(\phi()\) 为GloRe模块。
Instance-wise Relation Distillation
Instance Feature Extraction
为了获取实例级关系,我们需要提取实例特征。通过gt来获取特征图上的实例特征,并使用ROI Align映射到同一大小
Instance-wise Relation Module and Distillation
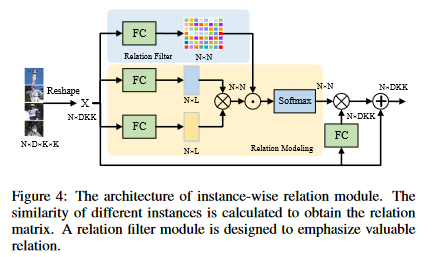
结构如图4所示,输入特征大小为 \(X \in R^{N \times DKK}\) 。N代表同一个图像中的实例个数,D代表实例特征的通道数,K代表实例特征图的大小。Instance-wise relation module 可以被表示为: \[ \psi\left(s_i,s_j\right)=\frac1\tau e^{w_{ij}g_1(s_i)g_2(s_j)},\tau=\sum_{\forall i}e^{w_{ij}g_1(s_i)g_2(s_j)} \] 其中 \(s_i\) 和 \(s_j\) 为实例特征,\(g_i\) 和 \(g_j\) 为全连接层。\(w_{ij}\) 是关系矩阵 \(W \in R^{N \times N}\) 权重,如图四过滤器所示。 \(\psi()\) 代表instance-wise relation feature。我们定义了instance-wise relation distillation function : \[ L_{IR}=\sum_{(i,j)\in\mathbb{N}^2}\left\|\psi\left(t_i,t_j\right)-f\left(\psi\left(s_i,s_j\right)\right)\right\|_2 \]
\[ L_{INS}=\frac{1}{n}\sum_{i=1}^{n}\left\|t_{i}-f(s_{i})\right\|_{2} \]
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!